1.연관어 분석이란..?
텍스트마이닝 분석 방법 중 하나로 연관어 분석(Association keyword analysis)이 있습니다.
연관어 분석이란 특정 단어가 어떤 맥락에서 등장하는지 파악하고,
단어들간의 관계성에서 의미를 파악하는 것입니다.
연관어 분석 중에서도 엔그램(N-grams) 분석 방법이 있습니다.
문장을 n개로 쪼개서 n개의 연결성을 보는 것인데요,
2개로 쪼개면 bi-grams, 3개로 쪼개면 tri-grams, 4개로 쪼개면 quad-grams 으로 분석이 됩니다.
예를 들면,
나는 행복합니다 이글스라 행복합니다. 라는 문장이 있다고 치면,
bi-grams 로 분석했을 때
'나는'-'행복합니다'
'행복합니다'-'이글스라'
'이글스라'-'행복합니다'
라고 결과가 나올 수 있습니다.
이 분석결과를 보면 상당히 이글스 팬인 것을 짐작할 수 있을듯 합니다..?ㅎㅋㅋㅋ
결과적으로 , 연관어 분석에서
단어들이 얼마나 '동시에' 출연하는지를 살펴봐야하고,
이 동시에 나오는 단어들이 어떤식으로 관계를 맺고 있는지 파악해야 합니다.
중요한 단어인 만큼 특정단어에 집중되어 '중심성'을 살펴볼 수 있습니다.
핵심단어 일수록 여러 단어들과의 관계가 다양하게 나타나게 될텐데요..
특히 연관어 분석에서는 '네트워크 그래프'가 필수입니다.
그래야, 단어들이 어떤식을 관계를 맺고 있는지 한 눈에 파악하기 편하니까요.
이렇게 말만 주구장창 하는 것보다 역시 데이터로 샘플을 봐야 좋겠죠..ㅎㅋㅋ
2.분석예시
그럼 이제 분석을 ㅎㅋㅋㅋ
계속 사용하던 댓글 세트를 사용합니다.
먼저, 형태소 분석을 실시합니다.
reply <- reply_naver %>%
unnest_tokens(input = reply,
output = word,
token = SimplePos22,
drop = F)

tidyr 패키지의 separate_rows 함수를 사용해서 행을 나누어 줍니다.
separate_rows(word, sep = "[+]") 이렇게 입력하면, "+"가 나올 때마다
행을 나누어줍니다.
그리고 filter와 str_detect 함수를 사용해서 '명사'만 찾아서 따로 저장해줍니다.
filter(str_detect(word, "/n")) %>%
이러면, word 라는 열에서 '/n'을 찾아 따로 정리해줍니다.
이어서, str_remove 를 써서 특수문자들을 지워주고
mutate(word = str_remove(word, "/.*$")) %>%
두 글자 이상인 값만 남도록 조정해줍니다.
filter(str_count(word) >= 2) %>%
그리고 arange 함수를 써서 id순으로 정렬되도록 합니다.
arrange(id)
이것들을 종합하면..
reply_noun <- reply %>%
separate_rows(word, sep = "[+]") %>%
filter(str_detect(word, "/n")) %>%
mutate(word = str_remove(word, "/.*$")) %>%
filter(str_count(word) >= 2) %>%
arrange(id)
이걸 실행하면
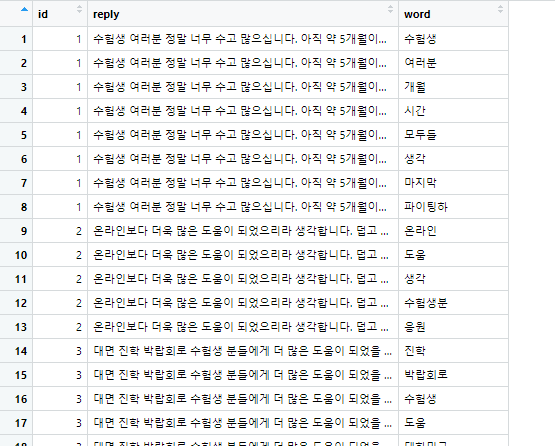
이런 결과물로 단어들이 정리되고,
불용어를 한 번 걸러보겠습니다.
reply_noun <- reply_noun %>%
filter(!word %in% stopword)
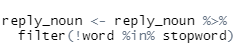
사진 설명을 입력하세요.
*stopword는 저번장에서 따로 지정해두었던 그놈들 입니다.

하고 나도 좀 이상한 단어들이 섞여서 거르질 못했나봐요.. 저런 놈들은 따로 걸러줍니다.
특히 "^ㅈ^ㄴ어려웠는" 이놈..
reply_noun <- reply_noun %>%
mutate(word = ifelse(word == "^ㅈ^ㄴ어려웠는","어려웠는",word))
이렇게 하면 바꿔줄 수 있습니다.
mutate 함수에, word = ifelse(word == "수정대상단어", "수정될단어", word ) 이런 식입니다.
그래서 아예 삭제를 하고 싶다면, 저 "수정될단어"를 ""로 안에 띄어쓰기도 없이 쌍따옴표를 쓰면 됩니다.
전반적으로 스윽 보면서 다 고쳐야 하는데
(한글 텍스트마이닝의 엄청난 단점..)
여기선 귀찮으니 넘어갑니다.ㅎㅎㅋㅋ
이제 각 댓글별로 '명사'만 남긴 상태입니다.(불용어를 완벽히 처리했다면 ㅎㅎㅋㅋ)
다시 이 친구들을 하나로 합쳐줍니다.
reply_new <- reply_noun %>%
group_by(id) %>%
summarise(sentence = paste(word, collapse = " "))
group_by 함수를 써서 id별로 묶어주고,
summarise 함수를 사용해, 'sentence'라는 열을 생성하고, paste 함수로 " " 단위로 묶어줍니다.
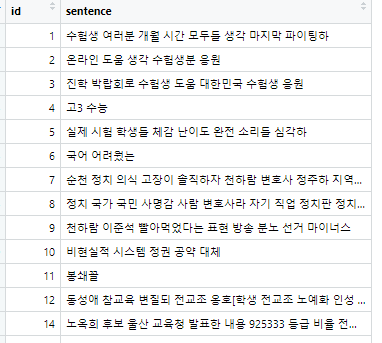
이러면, 명사들끼리 잘 뭉쳐져 있게 됩니다.
이럼 이제 n-grams로 분석 들어갑니다잉
reply_bigram <- reply_new %>%
unnest_tokens(input = sentence,
output = bigram,
token = "ngrams",
n = 2)
앞서 형태소분석과 다른 것은,
token = 'ngrams'로 바꾼 것,
n= 2 로 bigram 분석이 되도록 설정한 것입니다.
(input, output 도 이름만 바뀐 것은 눈치채셨을 것이라 믿고..)
그 결과를 보면 이렇게 ..

이제 이 단어들을 다시 2개 단어로 분리해줍니다..ㅋㅋㅋ(분리했다 합쳤다 분리했다..어휴..)
그리고, 그 와중에 혹여나 같은 단어끼리 나오면 크게 의미를 부여하기 어려우니,
그런 경우는 따로 지워줍니다.
reply_bigram2 <- reply_bigram %>%
separate(bigram, c("word1", "word2"), sep = " ") %>%
filter(word1 != word2)
separte 함수를 써서 bigram이라는 열을 'word1'과 'word2'로 분리하고, 단위는 " " 로 합니다.
그리고
filter(word1 !=word2 ) 같은 단어는 거르도록 설정합니다. 이러면?
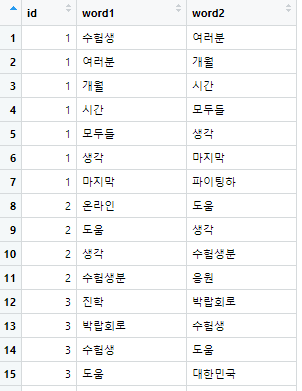
또 이렇게 찢어놓습니다.
이제 이 단어들이 몇 번 등장하는지 카운트를 합니다.
reply_count <- reply_bigram2 %>%
count(word1, word2, sort = T) %>%
filter(str_count(word1) >= 2) %>%
filter(str_count(word2) >= 2) %>%
na.omit()
count 함수를 써서 word1, word2 를 각각 세고
filter를 써서 각 단어 쌍이 2번 이상인 것만 나오도록 하고
na.omit으로 결측치는 삭제합니다.
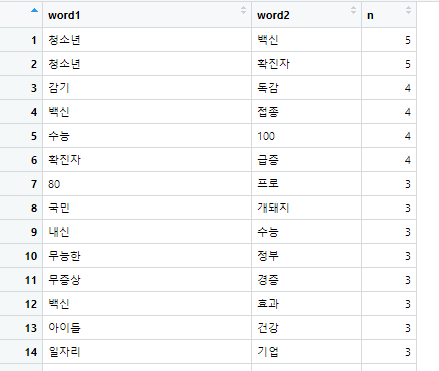
이러면, 각 단어쌍 별로 몇 번씩 등장하는지 나옵니다.
애초에 로데이터가 작아서.. 그래프가 그렇게 이쁠 것 같진 않은데..
암튼 이제 그래프만 그리면 끝입니다.
그래프 그리는데 필요한 패키지는
library(ggraph)
library(showtext)
library(tidygraph)
그리고
bigram_graph <- reply_count %>%
filter(n >= 2) %>%
as_tbl_graph(directed = F) %>%
mutate(centrality = centrality_degree(),
group = as.factor(group_infomap()))
filter(n >= 2) %>% : 단어쌍이 2번 이상 나오는 것들로 거르고
as_tbl_graph(directed = F) %>% : 뭔진 모르겠지만, ..이렇게 설정해주고..
mutate(centrality = centrality_degree()
group = as.factor(group_infomap()))
이걸로 '중심성'계수를 설정하고, group별로 묶일 수 있도록 만들어줍니다.
이걸 설정하면 'list' 묶음으로 저장되서 바로 확인하기 어려운데,
civa <- as.data.frame(bigram_graph)
데이터프레임으로 따로 지정한 다음,
결과값을 보면
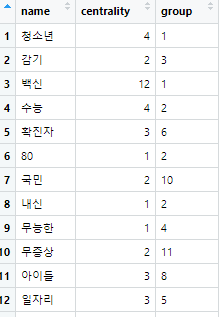
각 단어별로 어떤 단어가 가장 집중되는지, 그룹별로 살펴볼 수 있습니다.
예를 들면, 1번 그룹에서 백신의 중심성이 12라서 아무래도 제일 큰 것 같은데,
1번 그룹은 대게 '백신'이라는 단어를 중심으로 단어들이 모여있다고 보면 됩니다.
*이때 주의할 점은 그래프를 그리기 위해 설정하는 filter(n >= 2) %>% 이 부분
여기서 저는 2로 정해도 그래프가 그렇게 복잡하게 그려지지 않는데,
만약 다른 내용을 긁어모아서, 단어쌍 수가 막 평균 20, 30, 50 정도로 나오는데
'2'이상인 것들만 긁으면 그래프가 엄청 복잡해지겠죠..?
그래서 적당히 덜 복잡하고 핵심만 볼 수 있도록 단어쌍의 숫자에 맞게 잘 설정해서
그래프 그리는 것도 중요합니다.
그 다음, ggraph 함수를 써서 값을 넣고 실행해줍니다.
set.seed(1234)
ggraph(bigram_graph, layout = 'fr') +
geom_edge_link(color = 'gray50',
alpha = 0.5) +
geom_node_point(aes(size = centrality,
color = group),
show.legend = F) +
scale_size(range = c(4,8)) +
geom_node_text(aes(label = name),
repel = T,
size = 5) +
theme_graph()
(그래프.. 진짜 잘 모르겠어서..ㅋㅋ 저저번 장에서 소개한 책을 참고하시면.. 좋을 것 같습니닿ㅎ)
이를 연달아 실행하면,
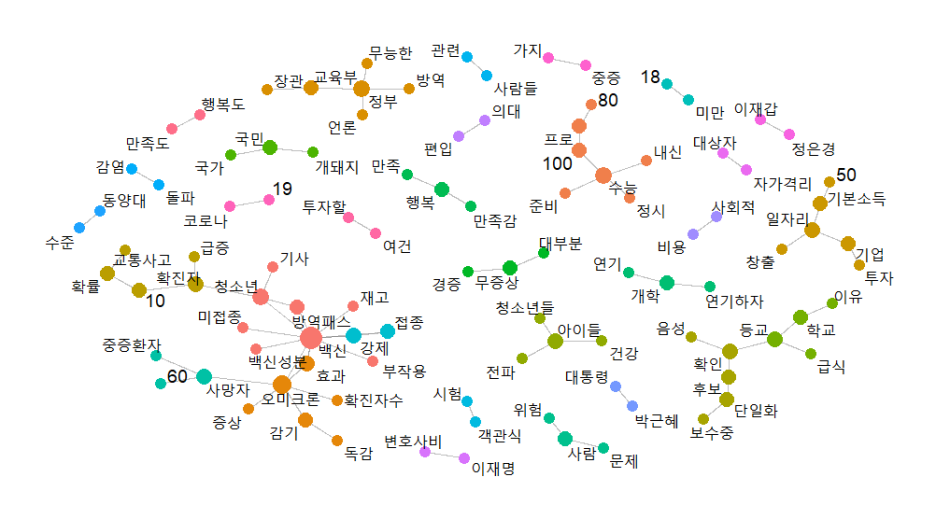
이런 그래프가 짜잔
분명 '수능'기사를 크롤링 했는데
다양한 그룹들이 형성되고 있네요
진짜 수능이야기를 하고 있는
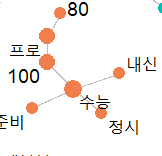
사진 설명을 입력하세요.
이런 그룹도 있고
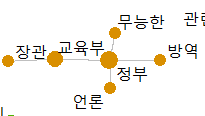
사진 설명을 입력하세요.
정부 욕하는 그룹도 보이고(ㅋㅋㅋㅋ)
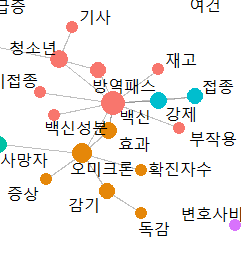
백신관련 내용을 언급하는 그룹도 있네요.
이렇게 네트워크 그래프를 그리면서 보면, 참 재밌는(?) 내용들을 볼 수 있답니다 ㅋㄷㅋㅋㅋ
'교육통계 > 텍스트마이닝' 카테고리의 다른 글
| 텍스트마이닝-웹크롤링(2) (0) | 2022.11.03 |
|---|---|
| 텍스트마이닝-웹크롤링(1) (0) | 2022.11.03 |
| 텍스트마이닝-토픽모델링 (0) | 2022.11.03 |
| 텍스트마이닝-단어빈도, 워드클라우드 (0) | 2022.11.03 |
| 텍스트마이닝-형태소분석 (0) | 2022.11.03 |