한글을 대상으로 하는 텍스트 마이닝을 할 때
필수 설치 패키지가 있습니다.
1. KoNLP 패키지 설치
바로 KoNLP
KoNLP에 등록된 함수를 주로 사용합니다.
이거 없으면.. 아마 아무도 못할껄요..
R 환경이 계속 불안정해서 그런지
이게 설치된다 안된다 말이 많아서,
이렇게 저렇게 다양한 해결방법이 있습니다.
일단 제 컴퓨터 기준으로 설치된 방법은
https://e-datanews.tistory.com/155
이곳을 참조했습니다.
install.packages("multilinguer")
library(multilinguer)
install_jdk()
install.packages(c("hash","tau","Sejong","RSQLite","devtools","bit","rex","lazyeval","htmlwidgets",
"crosstalk","promise","later","sessioninfo","xopen","bit64","blob","DBl","memoise","plogr",
"covr","DT","rcmdcheck","rversions"),type = "binary")
install.packages("remotes")
remotes::install_github('haven-jeon/KoNLP',upgrade = 'never', INSTALL_opts=c("--no-multiarch"))
library(KoNLP)
2. 형태소 분석
분석에 앞서 도움이 매우 될만한 책을 한 권 소개해드리면,

Do it! 쉽게 배우는 R 텍스트 마이닝(김영우 저)
ebook으로도 판매를 하고 있어서, 분석할 때 헷갈리고 모르겠는 거 여기 많이 참고했습니다 ㅎㅋㅋ
한글 텍스트 마이닝을 위해선 형태소 분석이 필수입니다.
텍스트 마이닝이 시작된 미국(?) 영미권에서
분석의 가장 작은 단위로 '단어'가 사용됩니다.
영어라는 언어에서 의미를 담은 가장 작은 단위는 '단어'
마찬가지로 한글에서 의미를 담은 가장 작은 단위는 '형태소'입니다.
일단 형태소 단위로 쪼개 놓고, 분석을 시작하죠.
분석에 앞서, 앞장에서 크롤링한 데이터가 있으리라 믿고..ㅎ
저는 제가 가지고 있는 크롤링 데이터를 활용합니다.
그새 댓글이 삭제된 건지 하나 없어졌네요..ㅎㅋㅋ
이 댓글 데이터를 활용해서 분석을 실시합니다.
library(KoNLP)를 불러온 상태에서,
useNIADic() 를 실행하여 사전을 구성해줍니다.
파이프 연산자 %>%를 자주 사용하는지라,
library(dplyr)도 불러와줍니다.
형태소 분석은 문장을 품사별로 분류하여 일종의 기호를 붙이는데,
https://github.com/haven-jeon/KoNLP/blob/master/etcs/figures/konlp_tags.png
{kind=link}
품사 표는 위 링크를 참조하시면 되겠습니다.
KoNLP에서 실행할 수 있는 형태소 분석은 두 가지,
SimplePos09와 SimplePos22 입니다.
뭐.. 바로 실행해서 보는 게 이해하기 더 좋을 것 같아서,
noun2 <- reply_naver %>%
unnest_tokens(input = reply,
output = word,
token = SimplePos09,
drop = F)
noun1 <- reply_naver %>%
unnest_tokens(input = reply,
output = word,
token = SimplePos22,
drop = F)
unnest_tokens 함수를 사용해서,
input = 분석할 대상,
output = 분석한 결과를 저장할 곳,
token = 분석방법
drop = F (False로 설정해야 raw data가 사라지지 않습니다.)
실행 결과를 보시면,
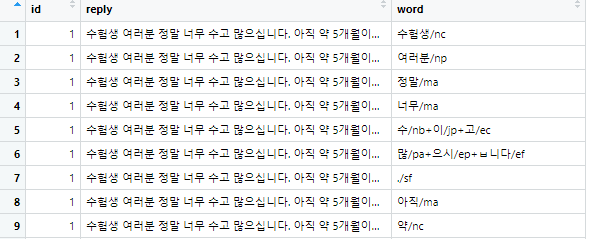
SimplePos09

SimplePos22
품사 표에 따라서 이렇게 저렇게 분석해서 태그를 붙여놓습니다.
그래서 뒤에 태그가 '명사(n)'가 달린 단어만 뽑아서 볼 수도 있지만,..ㅋ
extractNoun이라는 좋은 방법도 있습니다.
noun <- reply_naver %>%
unnest_tokens(input = reply,
output = word,
token = extractNoun,
drop = F)
말 그대로 명사만 뽑아오게 하는 방법인데,
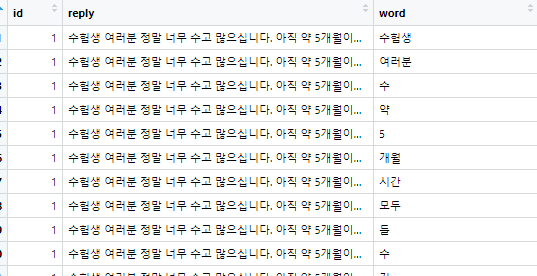
다른 태그 없이 '명사'로 판별한 것만 가져옵니다.
이제 진짜 텍스트 마이닝 분석을 위한 기초자료 준비는 끝난 것 같습니다.
문장들을 단어 단위로 쪼개고, 의미가 담긴 가장 작은 단위 형태소만 남겨놓고
분석을 시작하면 됩니다.
'교육통계 > 텍스트마이닝' 카테고리의 다른 글
| 텍스트마이닝-웹크롤링(2) (0) | 2022.11.03 |
|---|---|
| 텍스트마이닝-웹크롤링(1) (0) | 2022.11.03 |
| 텍스트마이닝-토픽모델링 (0) | 2022.11.03 |
| 텍스트마이닝-연관어분석 (2) | 2022.11.03 |
| 텍스트마이닝-단어빈도, 워드클라우드 (0) | 2022.11.03 |