저번 장에 이어서
1. 링크를 정리해서
2. 기사의 언론사, 시간, 제목, 본문, 댓글 수를 긁어 데이터 프레임으로 조직한 다음
3. 댓글 내용만 따로 다시 정리하는 작업을
이어서 해보겠습니다.
1. 네이버뉴스 링크 긁어오기
브라우저를 원격 조종할 때, 주로 xpath를 사용했습니다.
이번에 사용할 함수는 'html_nodes'이어서,
이번에 활용하는 것은 'css'입니다.
css구조를 통해서 html의 text를 긁어오는 그런 것으로..(아마도..?)
일단.. 저번 화면에서 이어서 시작하면
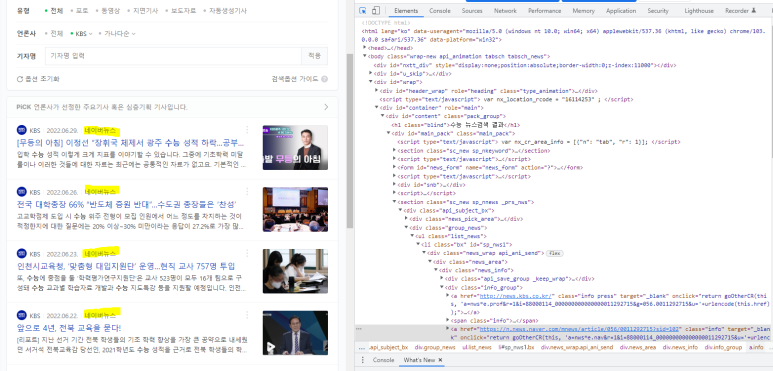
개발자 모드를 활성화시킨 상태에서 보면,
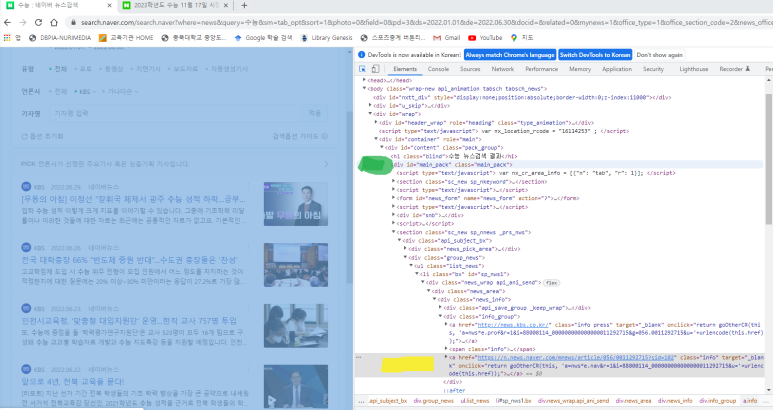
#mainpack 으로 잡힌 초록색 부분에서
아래
'a href = ~' 이렇게 두 곳을 주목해서 보면 됩니다.
a href 부분이 '네이버뉴스'로 연결해주는 하이퍼링크를 담고 있어서,
이 두 가지만으로 링크를 긁어올 수 있습니다.
R로 돌아가서.
link_nnews 백터를 생성해서, 링크를 담아줄 준비를 합니다.
link_nnews <- c()
그다음, html을 일단 긁어옵니다.
getPageSource()를 사용하면, 해당 페이지의 오만 잡다한 것 다 가져오게 되는데,
[[1]]로 인덱스를 달아두면, html 정도만(?) 담아옵니다.
그래서 다시 이걸 body라는 객체에 다시 read_html()를 사용해서
html구조를 담아줍니다.
frontpage <- remDr$getPageSource()[[1]]
body <- frontpage %>% read_html()
html 구조를 담아준 body를 사용해서
html_nodes()와 html_attr()를 사용해서,
특정 css구조를 설정해주고, 설정된 css구조 내의 하이퍼링크를 가져옵니다.
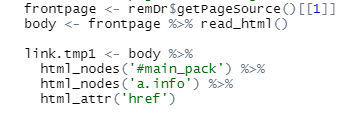
link.tmp1 <- body %>%
html_nodes('#main_pack') %>%
html_nodes('a.info') %>%
html_attr('href')
그러면, 결괏값이
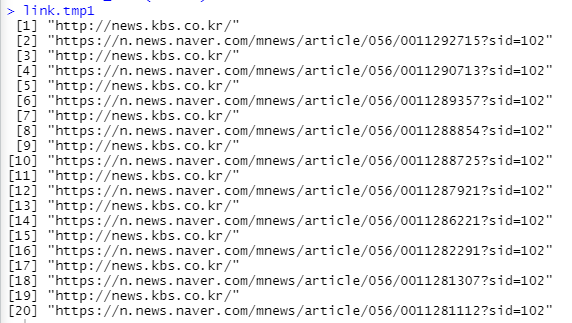
구조 내에 있던 링크를 싹 긁어옵니다.
이걸로 끝나면 좋겠지만,
다음 페이지에 있는 기사들도 긁어와야 하니까..
xpath를 사용해서, 다음 페이지로 가는 명령어를 또 만들어줍니다.ㅎ
(잘 찾으실 것이라 믿고..)
이렇게 계속 무한 반복하기는 귀찮(?)으니까..
for구문을 사용해서 자동화시켜봅시다.ㅎ
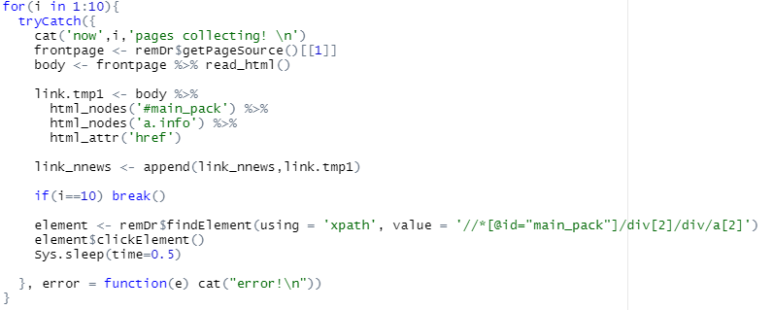
for(i in 1:10){
tryCatch({
cat('now',i,'pages collecting! \n')
frontpage <- remDr$getPageSource()[[1]]
body <- frontpage %>% read_html()
link.tmp1 <- body %>%
html_nodes('#main_pack') %>%
html_nodes('a.info') %>%
html_attr('href')
link_nnews <- append(link_nnews,link.tmp1)
if(i==10) break()
element <- remDr$findElement(using = 'xpath', value = '//*[@id="main_pack"]/div[2]/div/a[2]')
element$clickElement()
Sys.sleep(time=0.5)
}, error = function(e) cat("error!\n"))
}
간단하게, 10페이지 정도만 생각해서 for(i in 1: 10) 으로 설정했습니다.
tryCatch를 사용해서, 진행상태를 메시지로 나타내게 작성하였고,
긁어온 링크는 append함수를 사용해서, link_nnews 객체에 이어 붙여 놓았습니다.
그리고 if(i == 10) break()를 넣고
element는 다음 페이지로 넘어가는 명령문입니다.
이후 에러가 나오면, error 메시지가 나오도록 표시해주었습니다.
무사히 실행된다면,
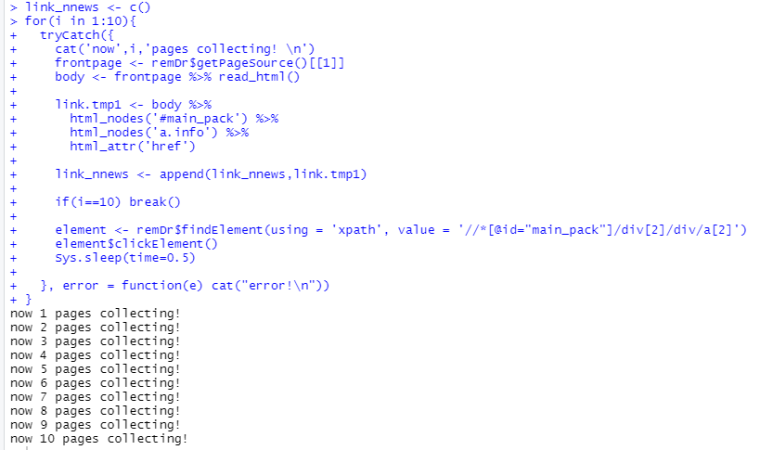
이렇게..
결괏값을 확인한다면,
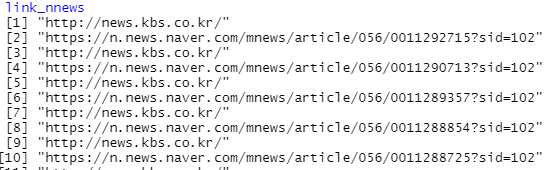
news.kbs.co.kr과 n.news.naver.com이 반복되는데,
일단 unique로 중복 값을 싹 지워줍니다.
link_nnews <- link_nnews %>% unique()
그다음 제가 필요한 것은 '네이버'뉴스지, 'kbs'도메인이 아니니까..
grep를 사용해서, 네이버 뉴스만 싹 정리합니다.
news.naver <- grep("https://n.news.naver",link_nnews)
grep를 사용하면, 'https://n.new.naver'로 시작하는 열 번호를 알려줍니다.

이 번호를 사용해서, 네이버 뉴스만 뽑아줍니다.
link_news.naver <- link_nnews[news.naver]

이러면 일단, 네이버 뉴스 링크만 뽑아내었네요!
2. 기사 언론사, 시간, 제목, 본문, 댓글 수 긁어모으기
사실 링크만 있으면 댓글을 긁어오는데 아무 문제가 없습니다.
하지만.. 데이터 전처리 작업이 필요하죠
일단 긁어모았는데, 전혀 상관없는 기사가 포함되거나 그러면,
나름의 '표본집단'이 오염될 것입니다.
따라서, 어떤 기사가 모였는지 따로 정리해서 확인한 후
필요 없는 기사는 삭제해서, 필요자료만 잘 모으는 것이 중요합니다.
제가 정리하려는 목록은
언론사/시간/제목/내용/url/댓글수 이렇게 6가지입니다.
이 6가지에 대한 객체를 만들어줍니다.
media_news.naver <- c()
date_news.naver <- c()
title_news.naver <- c()
content_news.naver <- c()
url_news.naver <- c()
replycount_news.naver <- c()
그다음, 조종하고 있는 브라우저를 모아 두었던 네이버 뉴스 링크로 이동시킵니다.
remDr$navigate(link_news.naver[1])
R뷰어가 이렇게 네이버 뉴스로 이동한 다음에 작업을 시작하는 게 좋습니다.
앞서 링크 긁어온 것과 비슷합니다.
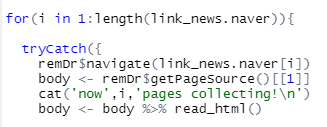
remDr$navigate(link_news.naver[i])
body <- remDr$getPageSource()[[1]]
cat('now',i,'pages collecting!\n')
body <- body %>% read_html()
이렇게 첫 페이지, html 구조를 가져올 수 있도록 조직해주고,
개발자 모드에서, css구조를 가져옵니다.
아..css구조는 copy- copy selector를 사용합니다.
#ct > div.media_end_head.go_trans > div.media_end_head_title > h2
이를 코드 명령문으로 정리하면,
title.tmp2 <- body %>%
html_nodes('#ct > div.media_end_head.go_trans > div.media_end_head_title > h2') %>%
html_text()
if(length(title.tmp2)!=0){
title_news.naver <- append(title_news.naver,title.tmp2)
} else {
title_news.naver <- append(title_news.naver,"check")
}
title.tmp2에다가 제목을 넣어주고,
아래 if 함수를 사용해서, 계속해서 내용이 나오면 append로 이어 붙이고,
없으면, 'check'이란 단어를 대체하도록 했습니다.

다음으로 보도 시간을 가져오면,
#ct > div.media_end_head.go_trans > div.media_end_head_info.nv_notrans > div.media_end_head_info_datestamp > div:nth-child(1) > span

본문 작성 시점에서는
#newsct_article 인 것 같습니다.
댓글 수는 링크를 통해 구할 수 있습니다.
사용하는 패키지는 'N2H4' 패키지입니다.
comments=N2H4::getAllComment(link_news.naver[i])
getAllComment를 사용해서 각 링크 별 댓글을 가져오고,
length를 활용해서 댓글 개수를 세어볼까 합니다.
comments=N2H4::getAllComment(link_news.naver[i])
if(length(comments$contents)!=0){
replycount_news.naver <- append(replycount_news.naver,length(comments$contents))
} else {
replycount_news.naver <- append(replycount_news.naver,"0")
}

url도 특별히 이상한 거 안 하고, append만 사용해서 다시 붙여 넣어줍니다.
이 오만 잡다하게 무진장 긴 식을 넣으면...
for(i in 1:length(link_news.naver)){
tryCatch({
remDr$navigate(link_news.naver[i])
body <- remDr$getPageSource()[[1]]
cat('now',i,'pages collecting!\n')
body <- body %>% read_html()
media.tmp2 <- body %>%
html_nodes('#contents > div.media_end_linked_more > div > a > em') %>%
html_text()
if(length(media.tmp2)!=0){
media_news.naver <- append(media_news.naver,media.tmp2)
} else{
media_news.naver <- append(media_news.naver,'')
}
date.tmp2 <- body %>%
html_nodes("#ct > div.media_end_head.go_trans > div.media_end_head_info.nv_notrans > div.media_end_head_info_datestamp > div:nth-child(1) > span") %>%
html_text()
if(length(date.tmp2)!=0){
date_news.naver <- append(date_news.naver, date.tmp2)
} else {
date_news.naver <- append(date_news.naver,"check")
}
title.tmp2 <- body %>%
html_nodes('#ct > div.media_end_head.go_trans > div.media_end_head_title > h2') %>%
html_text()
if(length(title.tmp2)!=0){
title_news.naver <- append(title_news.naver,title.tmp2)
} else {
title_news.naver <- append(title_news.naver,"check")
}
content.tmp2 <- body %>%
html_nodes("#newsct_article") %>%
html_text()
if(length(content.tmp2)!=0){
content_news.naver <- append(content_news.naver, content.tmp2)
} else {
content_news.naver <- append(content_news.naver,"check")
}
comments=N2H4::getAllComment(link_news.naver[i])
if(length(comments$contents)!=0){
replycount_news.naver <- append(replycount_news.naver,length(comments$contents))
} else {
replycount_news.naver <- append(replycount_news.naver,"0")
}
url_news.naver <- append(url_news.naver,link_news.naver[i])
Sys.sleep(time=1)
})
}
(바쁘신데.. 복붙 권장합니다..ㅎ)
무사히 에러 없이 잘 모였다면...
length() 함수로 각각 길이가 동일한지 확인합니다.
length(media_news.naver)
length(date_news.naver)
length(title_news.naver)
length(content_news.naver)
length(url_news.naver)
length(replycount_news.naver)
길이가 동일하지 않으면, 데이터 프레임으로 만들기 어려우니까요.ㅎㅋ
다만, 본문에는 이것저것 긁어오는 게 있는데
전처리를 살짝 해줍니다.
content_news.naver <- str_replace_all(content_news.naver,"\n", "")
content_news.naver <- str_replace_all(content_news.naver,"\t", "")
content_news.naver <- str_replace_all(content_news.naver,"//", "")
content_news.naver <- str_replace_all(content_news.naver,"function _flash_removeCallback()", "")
content_news.naver <- str_replace_all(content_news.naver,"//()", "")

그다음.. 데이터 프레임으로 만들어줍니다.
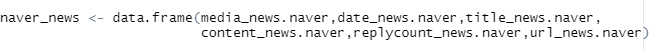
그리고 csv로 저장해 볼게요
이러면, R 워킹 디렉터리에 csv 파일이 생깁니다.
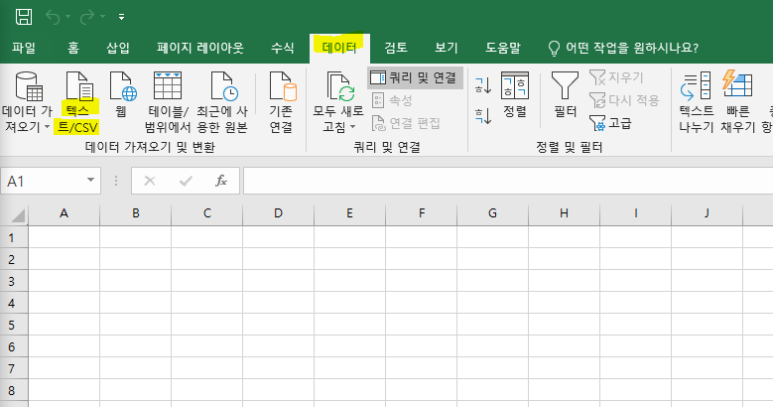
엑셀로 불러와볼까요??
엑셀로 가면 데이터 탭에 텍스트/CSV 불러오기가 있습니다.
불러오면...
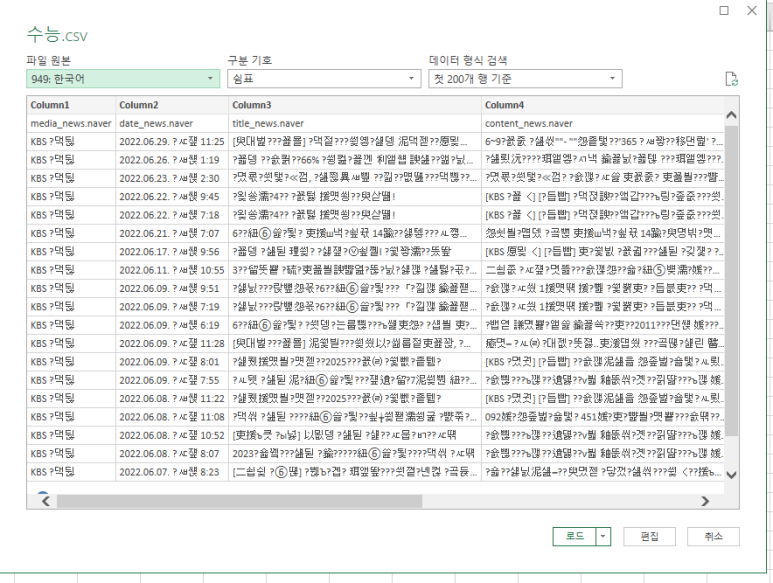
아니 이게 뭐야ㅣ;;;;
라면서 살짝 당황을 했지만..
당황하고 나서
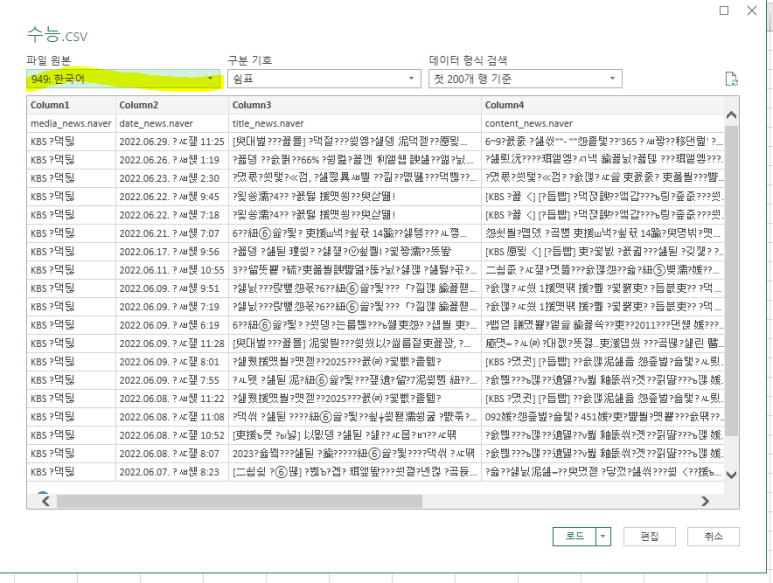
저기 한국어 표기를 눌러서 "없음"으로 처리를 해주면..?
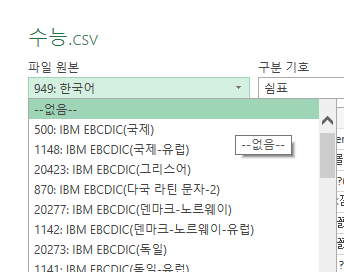
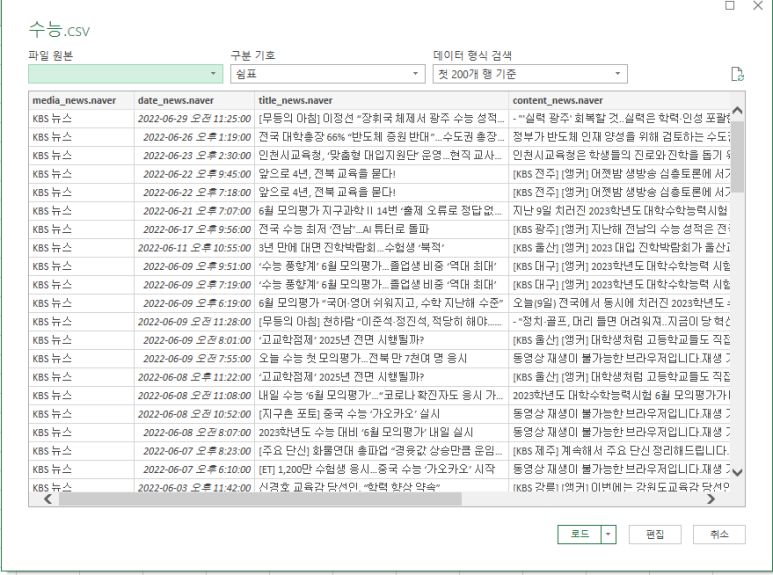
한글을 한글로 설정하면 못 읽는 댕청한 엑셀..
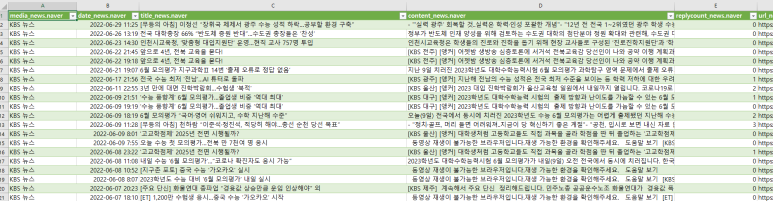
이렇게 필터까지 걸려서 설정이 됩니다.
여기서 이렇게 '원자료'를 확보하게 됩니다.
3. 댓글 내용만 따로 데이터 프레임으로 정리하기
아까 댓글 수 셀 때 사용했던 N2H4를 이용해서
실제 댓글을 정리해봅시다.
댓글을 담기 위한 객체를 만들어줍니다.
reply <- c()
그다음, for 구문을 사용해서
url이 있는 만큼 반복하도록 설정하고,
append를 사용해서 댓글들을 이어 붙여줍니다.
for(i in 1:length(naver_news$url_news.naver)){
comments=N2H4::getAllComment(naver_news$url_news.naver[i])
reply <- append(reply, comments$contents)
}

댓글을 열심히 긁어모으면,
length를 활용해 몇 개인지 확인합니다.
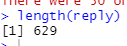
629개면... 이제 id 열을 따로 만들어서 데이터 프레임을 구성합니다.

이러면.. 텍스트 마이닝을 위한 데이터 수집이 완료됩니다..ㅎㅎ휴
데이터 수집이 참 어려운 게..
언론사가 한 둘이 아니니까..
링크 수집을 이것저것 다 모은 다음,
기사 정리해서 쓸데없는 기사들을 싹 다 지운 다음에
댓글을 모으면 됩니다.
이제 다음부터 텍스트 마이닝 분석방법을 다뤄볼 수 있겠네요;;ㅎㅎㅋㅋ
'교육통계 > 텍스트마이닝' 카테고리의 다른 글
| 텍스트마이닝-웹크롤링(1) (0) | 2022.11.03 |
|---|---|
| 텍스트마이닝-토픽모델링 (0) | 2022.11.03 |
| 텍스트마이닝-연관어분석 (2) | 2022.11.03 |
| 텍스트마이닝-단어빈도, 워드클라우드 (0) | 2022.11.03 |
| 텍스트마이닝-형태소분석 (0) | 2022.11.03 |