텍스트 마이닝이란
빅데이터 분석 방법 중 하나로, 이름에서 드러났듯이
텍스트를 분석하는 방법 중 하나이다.
텍스트 분석에서 일종의 내용 분석과도 유사한 부분이 있지만,
대량의 데이터를 분석하는 방법인 점에서 아마 차이가 있지 않을까..라고 생각해봤습니다 ㅋㅋ
텍스트 마이닝의 목적은 추출된 정보들을 활용해서 일종의 패턴을 발견하는 게 주목적으로 볼 수 있습니다.
태그에도 달아 두었지만,
특히 뉴스 댓글 같은 경우 수많은 사람들이 이래 저래 엄청나게 쓰지요
텍스트 마이닝을 활용한다면 댓글 수천개, 수만개 달린 것을 분석해서
댓글을 쓴 사람들이 어떤 이야기를 중심으로 이루어지고 있는지 살펴볼 수 있답니다(아마도..?)
텍스트마이닝 분석방법에는 대표적으로(?)
워드 클라우드(word cloud), 연관어 분석(association keyword analysis), 토픽 모델링(Topic modeling), 감성 분석(sentiment analysis) 등이 있습니다.
일단 분석을 하려면, 데이터를 수집해야겠죠??
데이터 수집을 위해 웹크롤링(web-crawling)을 사용하려 합니다.
-------------------------------------------------------------------------------------------------------------------------------
웹 크롤링을 사용하면 웹 브라우저를 통해 텍스트를 긁어모을 수 있습니다.
슬슬.. R로 시작해볼까요.ㅎ
1. Rselenium 활용한 크롤링 준비
크롤링 사용할 때 사용하는 함수로 'Rselenium'이 있습니다.
자세한 설명은 살짝 어렵고..(저도 뭐.. 그냥 '어 돌아가네? 이러면서 하는 거라..)
대신, 제가 공부하면서 큰 도움을 얻은 곳을 링크 달아둡니다.
https://youtu.be/_jyHGmXMRPk
나중에 언급할 댓글 긁어오는 함수를 개발자 분인지라(멋진 분이야 정말..)
여기서라도 다시 감사를 표하면서..ㅎㅋㅋ
다시, 어쨌든 Rselenium을 돌리는데 필요한 함수로
library(rvest)
library(httr)
library(RSelenium)
library(tidyverse)
이 친구들을 사용합니다.
위 함수들은 install.package()로 잘 설치가 되는 친구들이라 없다면, 설치하시면 됩니다.
그다음, 웹 크롤링인 만큼 웹브라우저가 필요한데,
위 유튜브 영상 보시면 아시겠지만,
'phantomjs'를 사용합니다.
그래서 이에 대해 wdman을 활용해서 객체에 넣어줍니다.
pJS <- wdman::phantomjs(port = 4569L)
여기서 항상 'port'를 설정해주시고, 실행을 했더니;;

이미 사용 중이라네요...
아까 연습할 때 써서 그런가.. 이런 메시지가 뜨게 된다면, 숫자만 바꿔서 다시 실행해줍니다.

오 잘 된 것 같네요..?
다음에, remoteDriver를 사용해서 다음과 같이 지정해줍니다.
remDr <- remoteDriver(port = 4561L, browserName = 'phantomjs')
이 'remDr'로 웹브라우저를 조종하게 됩니다.
remDr$open() 을 실행해주면,

뭐 이런 식으로 메시지가 쭈욱 뜹니다.
아 그럼 브라우저가 실행되고 있구나 생각하시면 됩니다.
브라우저를 열었으면, url을 넣어야겠죠?
remDr$navigate(url) 실행해줍니다.
url은 주소 가져와서 넣어줍니다.
여기 네이버니까.. 네이버 넣죠 뭐 ㅎ
remDr$navigate('https://www.naver.com/')

에러 메시지 없이 돌아간다면, 진짜 돌아가는지 어떻게 아는가 싶을 텐데요.
remDr$screenshot 을 활용하면 됩니다.
remDr$screenshot(display = T) 이대로 실행하면,
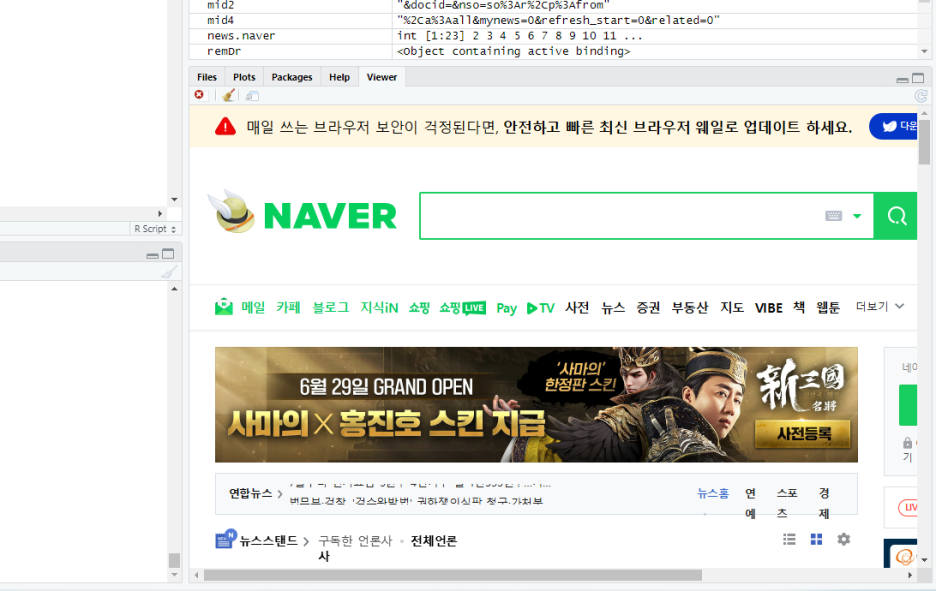
Viewer 창에 등장합니다.
시시각각 변하는 것을 동시에 보면 좋을 텐데..
(제가 했던 것은 크롬 브라우저를 원격 조종해서 실시간으로 검색하는 것을 보면서 할 수 있었는데, 웹 환경이 바뀌어서 그런 건지 도저히 안 되더라고요;; 하.. 그래도 이렇게 되는 게 다행이라 해야 할지..)
2. URL 조직
네이버 창을 띄우고 보니, 일단 제 목적은 뉴스의 댓글을 긁어오는 것이니까
바로 뉴스가 나오도록 url을 만들어서 넣어주면 좋지 않을까요?
보통(?) 뉴스가 나오는 url을 뜯어보면

https://search.naver.com/search.naver?
: 네이버 통합검색
''의 네이버 통합검색 결과입니다.
search.naver.com
를 일단 끊어보고
뒤에 'where=news&sm=tab_jum&query=축구'를 끊어보면,
'query=' 이거 뒤에 제가 찾고자 하는 주제, 단어를 넣으면 되는 것 같네요
여기에 '시점'까지 같이 넣어서 설정을 해주면
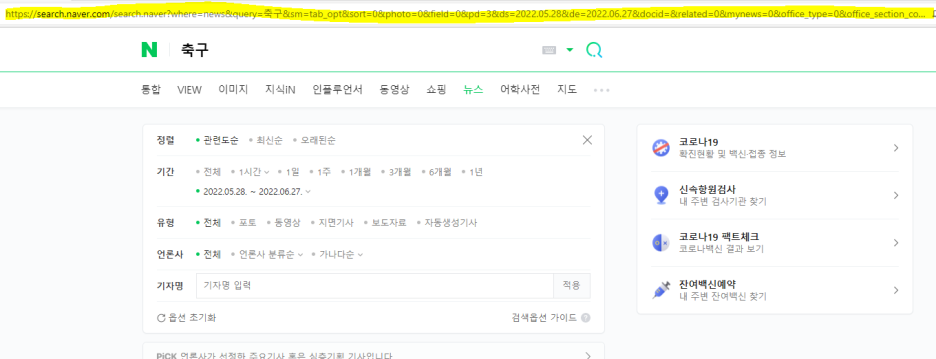
겁나 길어지네요..ㅋㅋㅋ
암튼 요점은 url을 조작해서 한 방에 바로 링크로 연결시키면
뭔가 편할 것 같습니다.
main <- "https://search.naver.com/search.naver?&where=news&query="
이거로 하나 잘라주고
다음에 검색할 키워드로 수능을 넣고
word <- "수능"
mid1 <- "&sm=tab_srt&sort=1&photo=0&field=0&reporter_article=&pd=3&ds="
중간에 나오는 거 넣어주고...
다음 url 구조상 검색 시점이 나옵니다.
start1 <- "2022.01.01"
from1 <- "&de="
end1 <- "2022.06.31"
이거 3개를 연달아 보면, 2022년 1월 1일부터 2022년 6월 30일까지 나오는 기사가 검색이 될 것 같네요
뒤에도 마찬가지로
mid2 <- "&docid=&nso=so%3Ar%2Cp%3Afrom"
start2 <- "20220101"
from2 <- "to"
end2 <- "20220630"
mid4 <- "%2Ca%3Aall&mynews=0&refresh_start=0&related=0"
다 따로따로 쪼개서 지정해줍니다.
이렇게 해야 검색시점 조정이 쉽지 않나 싶네요.
그럼 이제 이 친구들 조각모음을 해야겠죠
paste(객체1, 객체2, sep = "") 를 사용해서 target이란 객체에 담아봅니다.
target <- paste(main, word, sep = "")
target <- paste(target, mid1, sep = "")
target <- paste(target, start1, sep = "")
target <- paste(target, from1, sep = "")
target <- paste(target, end1, sep = "")
target <- paste(target, mid2, sep = "")
target <- paste(target, start2, sep = "")
target <- paste(target, from2, sep = "")
target <- paste(target, end2, sep = "")
target <- paste(target,mid4, sep = "")
이렇게 싸악 연결하면..

이렇게 길게 연결이 됩니다.
이제 이걸로 실행을 해볼까요

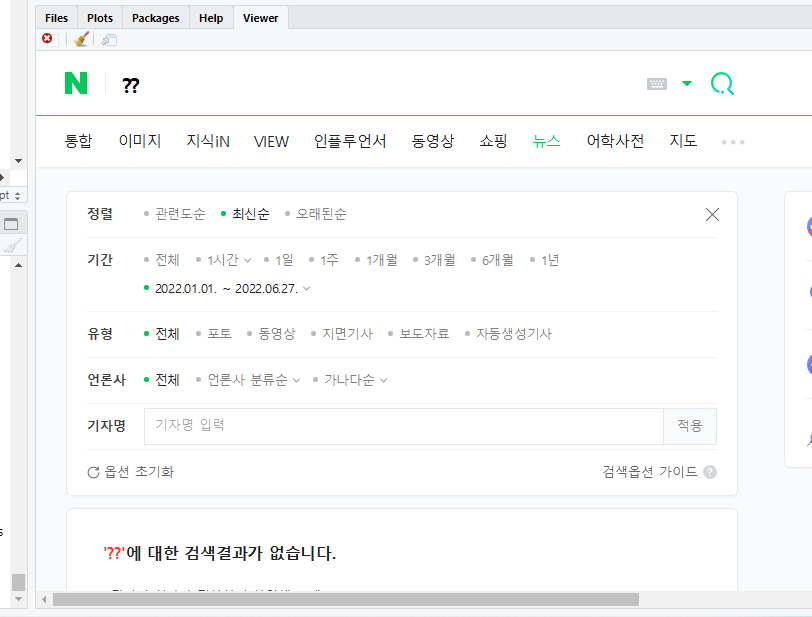
젠장...한글 인식을 못합니다.
이제 살짝 복잡해집니다..ㅋㅋㅋ
3. findElement 활용해서 해결해보아요
아까 언급드렸다시피, 원격조종 중입니다.
그러면, 저기 검색창을 건드려서 싹 지우고
원하는 키워드 넣고 다시 검색하면 되지 않을까요?
이를 위해 findElement를 사용합니다.
xml 또는 html의 주소를 활용해서 입력값을 넣고 컨트롤을 합니다.
페이지가 구성된 코드를 찬찬히 뜯어본다(?) 생각하면서 보면 될 것 같아요
저 친구들 구조에 대해선 위 유튜브 영상에서 확인하시는 게 이해가 더 빠르실 것 같습니다. ㅎㅎ
아무튼 xml 중 'xpath'를 사용해서 조종을 해봅니다.
그러면 이제 xpath는 어떻게 찾느냐...
크롬 브라우저를 켜줍니다..ㅋㅋ
아까 target으로 만들어둔 링크로 바로 타고 가시면,

저는 이렇게 나오네요ㅎ
크롬 화면에서 'F12'를 눌러줍니다.
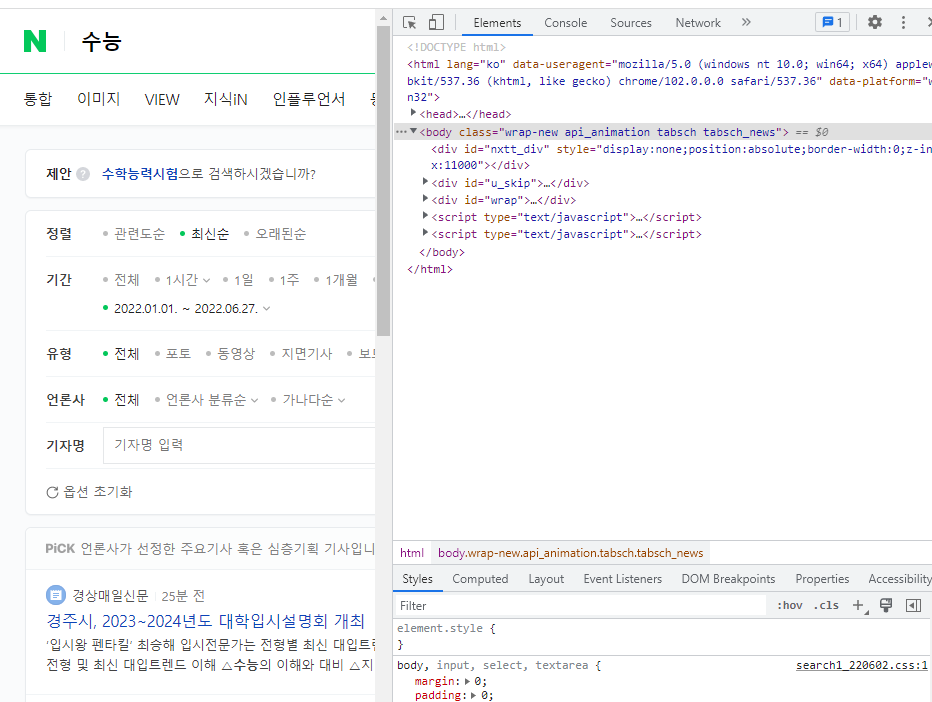
이렇게 개발자 탭이 등장합니다.
여기서

형광펜 부분
마우스 모양을 눌러보면,

마우스를 가져다 놓는 곳에 저렇게 활성화가 됩니다.
일단, 저 검색창을 치워야 하니 검색창에 마우스를 두고
오른쪽에 가서 마우스 우클릭, copy-xpath를 누르면 됩니다.
이렇게 글로만 쓰니 설명하기도 쉽지 않네요 ㅎㅋㅋ
복사한 거 잘 저장해두시고,
element에 지정을 해볼게요.
element <- remDr$findElement(using = 'xpath', value = 'xpath 복사한 거 그대로 넣기')
이대로 넣는다면..
element <- remDr$findElement(using = 'xpath', value = '//*[@id="nx_query"]')
element$clickElement()
Sys.sleep(time = 0.5)
이렇게 됩니다.
실행하고, 창을 살펴볼까요?

뭔.. 말 같지도 않은 것들이 겁나 나오는데 빨리 지웁시다 ㅋㅋ
다시 검색창에서 움직여야 하니, xpath는 동일하고요
위에서는 click을 했다면, 여기서 clear를 해줍니다.
그래서 사용하는 것은 clearElement
element <- remDr$findElement(using = 'xpath', value = '//*[@id="nx_query"]')
element$clearElement()
Sys.sleep(time = 0.5)
마찬가지로 실행해주고 살펴보면,

오?? 가 사라졌습니다.
다시 저 검색창을 눌러줍니다.
element <- remDr$findElement(using = 'xpath', value = '//*[@id="nx_query"]')
element$clickElement()
Sys.sleep(time = 0.5)

깔끔..
이제 검색 키워드를 넣어볼게요.
마찬가지로 같은 xpath이고
값을 입력할 때 'sendKeysToElement' 를 씁니다.
element <- remDr$findElement(using = 'xpath', value = '//*[@id="nx_query"]')
element$sendKeysToElement(list("수능"))
Sys.sleep(time = 0.5)
실행 후
다시 화면을 보면

키워드가 들어갔네요
그럼 이제 검색해야겠죠??
저 실행창 옆에 돋보기 xpath 찾으러 또 갑니다..
찾았다면..!
element <- remDr$findElement(using = 'xpath', value = '//*[@id="nx_search_form"]/fieldset/button')
element$clickElement()
Sys.sleep(time = 0.5)
입력해서 실행해줍니다!

검색이 된 것 같네요..ㅎㅎㅋ
4. 언론사 설정
한국에 신문사가 굉장히 많다는 것은
뉴스 슬쩍만 스크롤 내려보면 알 수 있습니다 ㅎㅋㅋㅋ
근데 문제는, 각 신문사마다 각기 독특한 html, xml을 구성하고 있다는 것입니다.
만약에 크롤링 코드를 짠다면, 각기 신문사마다의 xml을 찾아서 그걸 반영해서
새로 짜고.. 다시 적용하고 다르게 적용하고..
아우 언제 그러고 있습니까..
귀찮은데.. 네이버 제휴하고 있는 신문사만 합시다.
네이버 제휴하고 있는 신문사를 사용하면,
'네이버 뉴스'의 형태로 동일한 xml, html을 공유하고 있어서
언론사가 달라도 동일한 코드를 써서 크롤링이 가능합니다.
(뭔가.. 네이버 홍보하는 것 같네..)
예시로 KBS만 하려 합니다..
다시.. xpath 찾으러 출발~

이거 찾으러 가는 영상입니다.
xpath 복사해서
element <- remDr$findElement(using = 'xpath', value = '//*[@id="snb"]/div[2]/ul/li[4]/div/div[1]/a[2]')
element$clickElement()
Sys.sleep(time = 0.5)
잘 눌러졌다면,

이렇게 쭈욱 리스트가 나옵니다.
KBS는 방송이니까 방송 탭에 있겠죠..
또 저 방송/통신 xpath찾으러 갑니다..

찾아서 마찬가지로~
element <- remDr$findElement(using = 'xpath', value = '//*[@id="snb"]/div[2]/ul/li[4]/div/div[2]/div/div[1]/div/div/div/ul/li[2]/a')
element$clickElement()
Sys.sleep(time = 0.5)

이제 KBS 찾으러 갑니다 ~
element <- remDr$findElement(using = 'xpath', value = '//*[@id="snb"]/div[2]/ul/li[4]/div/div[2]/div/div[2]/div/div/div/ul/li[38]/a')
element$clickElement()
Sys.sleep(time = 0.5)
실행하면~~

kbs 뉴스만 나오네요..
아까 이야기했던 네이버 제휴를 맺으면 저렇게 '네이버 뉴스'창이 따로 있습니다.

이제 저 링크를 따오는 게 다음 목적지입니다.
일단... 여기까지만 하고 링크 잡는 거는 다음장으로 넘겨볼게요..ㅎㅎㅋ
지금까지 작업한 거 영상으로 올려보겠습니다!
*xml구조나, html구조는 개발자가 변경하게 되면
이전에 사용한 xml, html경로를 사용 못하더라고요..
그래서 구조 바뀌면.. 새로 코드 짜야되는 거는 어쩔 수 없습니다. 휴,.ㅋㅋㅋ
'교육통계 > 텍스트마이닝' 카테고리의 다른 글
| 텍스트마이닝-웹크롤링(2) (0) | 2022.11.03 |
|---|---|
| 텍스트마이닝-토픽모델링 (0) | 2022.11.03 |
| 텍스트마이닝-연관어분석 (2) | 2022.11.03 |
| 텍스트마이닝-단어빈도, 워드클라우드 (0) | 2022.11.03 |
| 텍스트마이닝-형태소분석 (0) | 2022.11.03 |