1. 토픽 모델링이란..?
텍스트 마이닝에 또 자주 쓰이는 방법론으로 토픽 모델링이라는 것도 있습니다.
대규모의 텍스트 데이터의 집합에서 주요 주제를 발견하고, 구조화하는 방법인데요.
토픽 모델링에서의 가정은
단어별로 특정한 '주제'를 담고 있다고 가정합니다.
그래서 특정 단어들이 자주 발견되는 데이터 구조, 문장 구조들이 형성되어 있으면
그 단어들이 의미하는 주제를 담고 있다고 봅니다.
예를 들어, 야구에 대한 같은 온라인 커뮤니티에 다양한 글들이 있겠죠.
이런 글, 저런 글 모으다 보면
특정 글에서는 '이글스 파이팅'이라는 주제를 담고 있는 데이터 구조가 형성되어 있을 수 있고
'이글스 해체해라' 등의 비방글도 있을 수도 있겠죠
이러한 주제들을 일일이 하나하나 확인하지 않고
통계 방법을 사용해서, 이러한 주제들을 추론해낸다고 보면 되겠습니다..
어떤 글에서 특정 주제를 포함하고 있는 단어에 일종의 '확률'을 부여해서,
그 단어가 자주 등장하는 글(집단)을 모아서,
이러한 단어가 주로 등장하게 되면 여기는 000 주제를 주로 다루고 있는 글(집단)로 봅니다.
제가 소개하려는 방법은 LDA(latent dirichlet allocation)방법입니다.
역시 실제 분석 예시를 보는 게 이해가 빠를 듯 싶습니다만 ㅎㅋㅋ
자세한 설명이 필요하시면,
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. the
Journal of machine Learning research, 3, 993-1022.
Blei, D. M. (2012). Probabilistic topic models. Communications of the ACM,
55(4), 77-84.
이 사람의 논문을 보는게 제일 정확(?) 할 듯싶기도 합니다.
통계.. 파라미터.. 등등의 이야기를 친절하게 하시더라고요.ㅎㅋㅋ
2. 분석 예시
분석방법을 찬찬히 살펴볼까요
LDA 분석을 위해서는 DTM(document- term matrix)가 먼저 필요합니다.
특정 글(문서, 집단) 별로 어떤 단어가 등장하고, 얼마나 등장하는지 보여줍니다.
일단 형태소 분석으로명사만 남기고..
불용어를 처리한 상태에서 시작합니다..!
noun <- reply_naver %>%
unnest_tokens(input = reply,
output = word,
token = extractNoun,
drop = F)
noun <- noun %>%
filter(str_count(word) >= 2) %>%
filter(!word %in% stopword)
다음 정리한 단어가 몇 번 등장하는지 count 함수로 세봅니다.
noun_count <- noun %>%
count(id, word, sort = T)
다음, tm패키지와 tidytext패키지를 활용해서
cast_dtm 함수를 사용해서 DTM을 만들어줍니다.
dtm_reply <- noun_count %>%
cast_dtm(document = id, term = word, value = n)
자 이제 바로 LDA 분석을 시작합시다! 하면 좋겠지만..
그전에 선행되어야 할 것이 있습니다.
LDA 분석에서는 연구자가 토픽의 수를 몇 개로 놓고 돌릴지 임의로 정하고 돌려야 합니다.
하지만..
그렇게 제 맘대로 하면 또 불편해하는 이들이 있기에 ㅋㅋㅋ
이를 보완하기 위해 perpelxity(복잡도)와 coherence(응집성)를 봅니다.
토픽의 개수를 2,3,.. n개로 정하면서
복잡도와 응집성이 어떻게 움직이는지 비교하면서
복잡도는 낮을수록, 응집성은 높을수록 적당한 토픽의 개수라 칭하고,
딱 그 토픽의 개수로 정한 대로 LDA 분석을 실시하게 됩니다.
먼저 복잡도를 구해볼까요 ㅎㅋㅋ
2-1. 복잡도 perplexity
일단 임의로 토픽의 개수를 총 10개까지 놓고, 어떤 값이 적절한지 살펴보고자 합니다.
n_topics <- c(2,3,4,5,6,7,8,9,10)
이렇게 지정해주시고,
필요한 패키지는
furrr, topicmodles 이렇게 2가지입니다.
library(furrr)
library(topicmodels)
다음에
lda_compare <- n_topics %>%
future_map(LDA, x = dtm_reply, control = list(seed =123))
future_map을 활용해서
LDA 분석으로, x = dtm 데이터, control = list(seed =123)으로 정해줍니다.
분석이 원활히 되었다면..
library(ggplot2)
ggplot2를 불러와서
아래 수식을 복붙 해서 실행하십시오..ㅎㅋㅋㅋ
tibble(
k = n_topics,
perplex = map_dbl(lda_compare, perplexity)
) %>%
ggplot(aes(k, perplex)) +
geom_point() +
geom_line() +
labs(
title = "Evaluating LDA topic models",
subtitle = "Optimal number of topics (smaller is better)",
x = "Number of topics",
y = "Perplexity"
)
그람
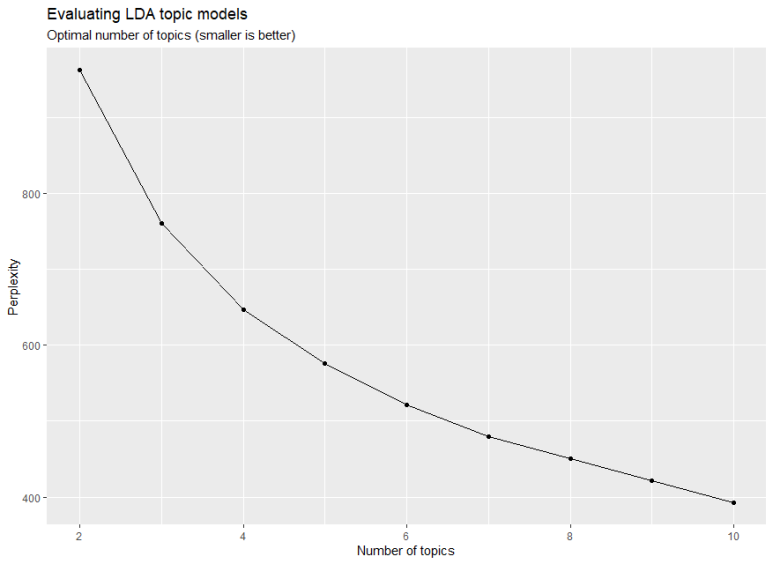
이런 그래프가 뜨악
x축은 토픽 수, y축은 복잡도 지수인데
토픽의 수가 증가할수록 복잡도가 점차 낮아지는 것으로 나오네요.
즉, 토픽 수를 높게 설정할수록 양호한 값이 나온다로 일단 정리하고
2-2 응집성 coherence
이제 응집성을 구하려 합니다.
필요한 패키지는 일단
library(topicmodels)
library(LDAvis)
library(servr)
library(Rmpfr)
library(textmineR)
library(tidyr)
library(dplyr)
요놈들..
CreateDtm 이란 함수를 사용하는데
new_topic_Model <- CreateDtm(doc_vec = noun$word,
doc_names = noun4$id,
ngram_window = c(1,2),
stopword_vec = c(stopwords::stopwords("en"), stopwords::stopwords(source = "smart")),
verbose = F)
대충 이런 식을 써서 구합니다.
마찬가지로 일단 dtm에서 시작을 해야 하는데..
아까 만들어 놓은 명사 'noun'을 활용해서 했더니 망할..
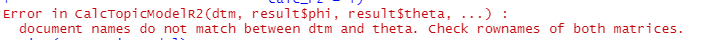
이딴 메시지를 보입니다. 뭐 이름이 안 맞다는데..
이게 보통 어떤 id 행에 단어가 없거나, id 자체가 중간에 사라져 있거나 그럴 때 이런 메시지가 뜨더라고요
어쩝니까 정리해드려야지
new_noun <- data.frame(noun$id, noun$word)
일단, 새롭게 데이터 프레임으로 지정해드리고
colnames(new_noun) <- c("id","word")
이름 좀 깔끔하게 바꿔드리고..
tmp1 <- new_noun %>%
group_split(id)
id 기준으로 단어들을 쪼개 놓습니다.
제가 만든 거로 쪼개 놓으면, tmp1이라는 객체에 '613'개가 쌓인다고 나옵니다.
Enviornment 에 있는 값 확인하세요!
set <- c()
빈 공간 만들어놓고 아까 그 613개를 다시 하나하나 정렬하는 for 구문을 만들어 놓았습니다.ㅋㅋㅋ
for(i in 1:613){
tryCatch({
s1 <- paste(tmp1[[i]], sep = "", collapse = NULL)
s1 <- gsub("^","",s1)
s1 <- gsub("ㅋ","",s1)
if(length(tmp1)!=0){
set <- append(set,s1)
}
}, error = function(e) cat("error!\n"))
}
paste는 ""기준으로 tmp1[[i]] 번째 오는 값들을 붙여라 이고,
gsub 함수를 쓰면, 특정 단어들을 여기서 삭제를 할 수 있습니다.
일종의 불용어 처리라고 보시면 되고,
이렇게 각각 1개씩을 append를 써서 c("")로 묶이도록 만들어줍니다.
이러면,

이런 식으로 묶입니다. 역시 Enviroment 창
그러면 총 1126개니까
id <- c(1:1226)
id에 1부터 1226까지 넣어주고
new_noun2 <- data.frame(id,set)
데이터 프레임을 또 만들어줍니다.
근데 제가 필요한 거는

숫자는 필요 없고, 한글이 들어있는 행이 필요합니다. 그래서..
new_noun2 %>%
mutate(g=id%%2) %>%
filter(g==0) -> new_noun3
mutate 함수로 'g'라는 열을 만들고, 이 열은 id를 2로 나눈 값이 오게 했습니다.
그다음 filter로 '0'인 값만 걸려서 new_noun3에다 집어넣습니다.
이러면 짝수행에 있는 한글만 오겠죠!?

이렇게?
그러면 이렇게 정리한 데이터셋이 총 613개로 나오는 것을 알 수 있습니다.
또 613을 지정하고..
id3 <- c(1:613)
new_noun4 <- data.frame(id3, new_noun3$set)
데이터프레임으로 만들어줍니다.
colnames(new_noun4) <- c("id","word")
이름 또 고치고..
이제 끝났습니다!
new_topic_Model <- CreateDtm(doc_vec = new_noun4$word,
doc_names = new_noun4$id,
ngram_window = c(1,2),
stopword_vec = c(stopwords::stopwords("en"), stopwords::stopwords(source = "smart")),
verbose = F)
여기에 볼드된 부분을 갈아 끼워 넣으면! 분석이 될 것입니다!!(제발..)
에러 메시지가 안 뜨면, 다음 식을 복붙에서 실행해주세요!
new_topic_Model2 <- FitLdaModel(dtm = new_topic_Model,
k=10,
iterations = 500,
alpha = 0.1, beta = 0.05,
optimize_alpha = T,
calc_likelihood = T,
calc_coherence = T,
calc_r2 = T)
이러면 열심히 계산해서 우리에게 가져다줍니다.
그리고 이제 제가 필요한 것은 coherence를 보여주는 그래프..
이 코드는 ..;.
new_topic_Model2$r2
plot(new_topic_Model2$log_likelihood,type = "l")
new_topic_Model2$top_terms <- GetTopTerms(phi = new_topic_Model2$phi,M = 15)
data.frame(new_topic_Model2$top_terms)
new_topic_Model2$coherence
new_topic_Model2$prevalence <- colSums(new_topic_Model2$theta)/sum(new_topic_Model2$theta)*100
new_topic_Model2$prevalence
new_topic_Model2$summary <- data.frame(topic = rownames(new_topic_Model2$phi),
coherence = round(new_topic_Model2$coherence,3),
prevalence = round(new_topic_Model2$prevalence,3),
top_terms = apply(new_topic_Model2$top_terms,2,function(x){paste(x,collapse = ", ")}))
modsum_5 <- new_topic_Model2$summary %>%
`rownames<-`(NULL)
modsum_5
modsum_5 %>% pivot_longer(cols = c(coherence)) %>%
ggplot(aes(x = factor(topic,levels = unique(topic)), y = value, group = 1)) +
geom_point() + geom_line() +
facet_wrap(~name,scales = "free_y",nrow = 2) +
theme_minimal() +
labs(title = "Best topics by coherence score",
subtitle = "Text review with 5 rating",
x = "Topics", y = "Value")
new_topic_Model2$linguistic <- CalcHellingerDist(new_topic_Model$phi)
new_topic_Model2$hclust <- hclust(as.dist(new_topic_Model$linguistic),"ward.D")
new_topic_Model2$hclust$labels <- paste(new_topic_Model$hclust$labels, new_topic_Model$labels[,1])
plot(new_topic_Model2$hclust)
이거 복붙에서 쓰시면.. ㅎㅎ 저기 볼드 된 거가 그래프 값입니다.
(저도 구글링으로 이거 저거 건드리면서 코드 짠 거라.. 어디서 어떻게 지정했는지 기억이 잘;;ㅎㅋㅋ
아마 이 코드 복붙해서 하나하나 실행하면 어떤 값들이 후두둑 등장할텐데.. 그런갑다 하고.. 혹은
추가로 구글링 하시면 도움이 될지도..?)
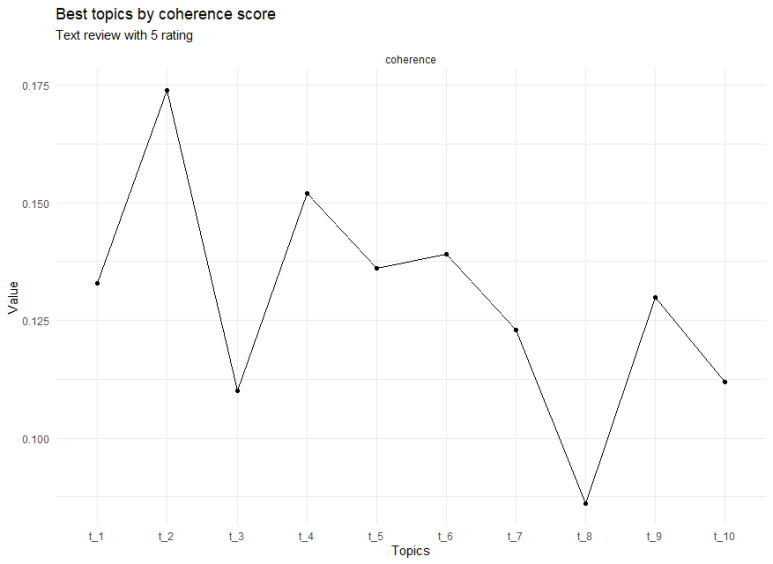
이렇게 coherence 그래프를 마주하게 됩니다ㅠㅠ
(불용어를 완벽하게 처리할수록 그래프는 예쁘게 나옵니다..
지금의 저로서는 너무 귀찮.. ㅎ)
보아하니.. 들쑥날쑥 하네욬ㅋㅋ
하지만 우리에게 복잡도 그래프도 있었으니,
적당히 토픽이 4개일 때, 적당히 응집성도 높고, 복잡도도 낮으니까
LDA분석은 4개로 놓고 하겠습니다!ㅎㅋㅋㅋ
3. 진짜 진짜 LDA분석
LDA분석 들어갑니다.
아까 그 perplexity 구할 때 사용했던 dtm을 사용합니다.
library(topicmodels)
lda_model <- LDA(dtm_reply,
k=4,
method = "Gibbs",
control = list(seed = 1234))
LDA 함수를 쓰고, dtm 넣고, k= 토픽 수, 방법은 "Gibbs", 넣고
이라면, dtm 속 단어들에 일정 확률을 계산해서 4개의 토픽으로 분류한 값이 나옵니다.
install.packages('reshape2')
위 패키지 설치해야 아래 가 실행되었습니다.
term_topic <- tidy(lda_model, matrix = 'beta')
이 값을 실행하면
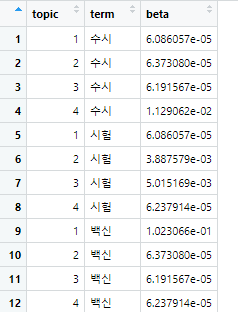
이런 식으로 어떤 단어가 몇 번째 토픽에 어떤 beta 값을 가지면서 들어가는지 보여줍니다.
이걸 이쁘게 그래프로 옮기면..!
terms(lda_model, 20) %>%
data.frame()
아까 단어들을 데이터 프레임으로 만들어주고
top_term_topic <- term_topic %>%
group_by(topic) %>%
slice_max(beta, n=10)
단어는 최대 10개까지만, beta 값이 높은 순으로!
library(scales)
library(ggplot2)
ggplot(top_term_topic,
aes(x= reorder_within(term, beta, topic),
y= beta,
fill = factor(topic))) +
geom_col(show.legend = F) +
facet_wrap(~ topic, scales = "free", ncol = 3) +
coord_flip() +
scale_x_reordered() +
scale_y_continuous(n.breaks = 4,
labels = number_format(accuracy = .01))+
labs(x= NULL)
그래프..ㅎㅋ
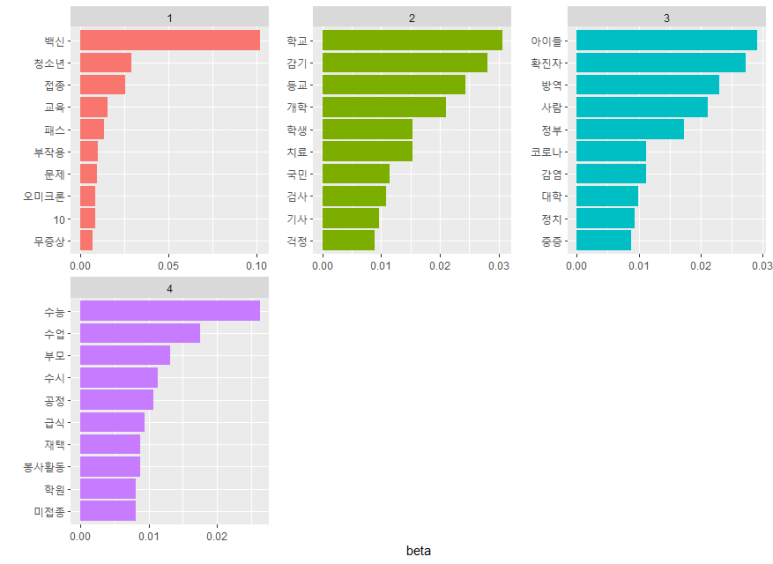
이렇게 4가지로 분류되고 있음을 알 수 있습니다!ㅎㅋㅋㅋ
이 그림 말고 다르게 그리는 방법은 역시
제가 추천드렸던 책에 상세히 나와있답니다.(다시 한 번 저자에게 감사..)
어떤 댓글들이 어떤 토픽으로 지정되었는지, 몇 개가 어떤 토픽에 달려있는지 보려면
doc_topic <- tidy(lda_model, matrix = 'gamma')
doc_class <- doc_topic %>%
group_by(document) %>%
slice_max(gamma, n = 1)
doc_class$document <- as.integer(doc_class$document)
쭈욱 실행하시다가
news_comment_topic <- reply_naver %>%
left_join(doc_class, by = c("id"="document"))
초기 댓글 데이터 프레임을 불러오게 합니다.
news_comment_topic %>%
select(id, topic)
이렇게 묶어서 따로 엑셀로 저장해서 본다면,
토픽 별로 몇 개의 댓글이 있는지 확인할 수 있습니다
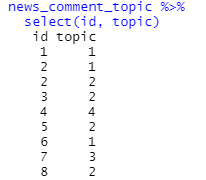
다시, 아래 화면으로 돌아오면
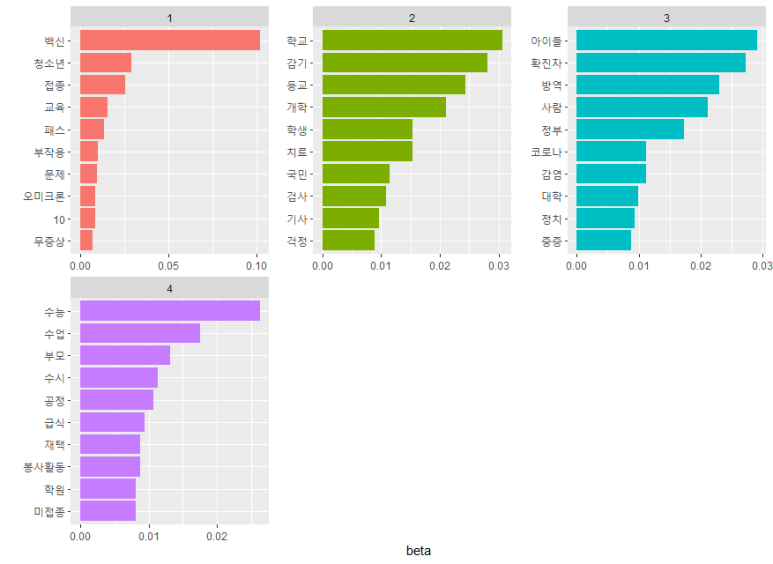
각각의 토픽에 대해서, 단어 모음집과 원 댓글들을 참고로 하여
토픽별 주제, 제목을 달아주어야 합니다.
(그래야 진짜 끝..)
대충 생각해보면,
1번은 청소년 백신 접종
2번은 대면 수업
3번은 학생 확진자 발생 시 대처 문제
4번은 수능 및 입시문제
라고 정해보겠습니다..(세상 대충ㅋㅋㅋ)
이렇게 짜잔 정했습니다 하고 끝나면 좋겠지만
혹시 어디 논문이나, 발표를 하신다면
이 제목들이 적절한지 꼭 타당도 평가를 받는 게 좋을 것 같습니다.
어디까지나 '연구자' 자신의 생각이니까
자신의 생각만으로는 이 결과를 뒷받침하기 어렵다고 다른 사람이 판단할 거예요
(위에 제가 대충 지은 걸 누가 받아들이겠어요 ㅋㅋㅋ)
타당도 평가 거쳐서 수정 의견 반영해서 한다면 그나마 설득력 있게
수능이라는 기사를 보고 사람들이 어떠한 반응을 나타내는지 서술할 수 있겠죠
아..이번 장 너무 길었네요 휴.
'교육통계 > 텍스트마이닝' 카테고리의 다른 글
| 텍스트마이닝-웹크롤링(2) (0) | 2022.11.03 |
|---|---|
| 텍스트마이닝-웹크롤링(1) (0) | 2022.11.03 |
| 텍스트마이닝-연관어분석 (2) | 2022.11.03 |
| 텍스트마이닝-단어빈도, 워드클라우드 (0) | 2022.11.03 |
| 텍스트마이닝-형태소분석 (0) | 2022.11.03 |