안녕하세요. 이번에는 매개효과에 대해 알아보도록 하겠습니다.
매개효과는 독립변수와 종속변수의 관계에서 영향을 줄 수 있는 제3 변수의 영향력을 확인하는 분석방법입니다.
말그대로 독립변수와 종속변수를 매개하는 변인이 존재한다는 가정에 따라서 분석을 하게 됩니다.
그림을 그려보면,
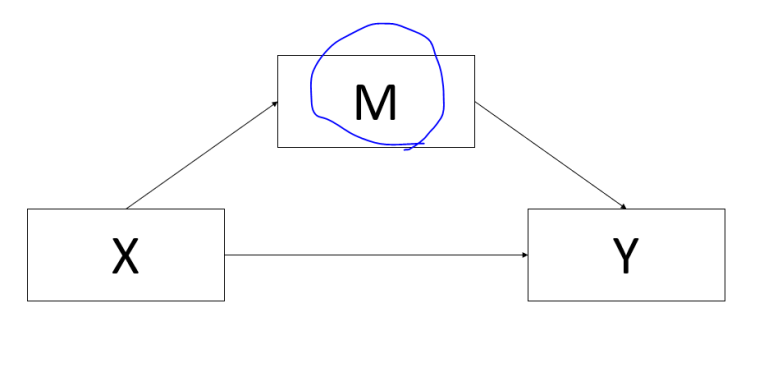
[그림 1] 매개효과 모형
X: 독립변수
Y: 종속변수
M: 매개변수
독립변수가 종속변수에 직접 효과를 줄 수 있지만, 매개변수를 통해서 간접적으로 영향(간접효과)을 줄 수 있습니다.
따라서 연구시에 매개 변인이 있는지 철저히 확인이 필요하며, 이에 따른 연구 설계가 중요합니다.
논리에 따라서 회귀분석으로 가능할지, 매개분석이 필요한지 결정해야 되겠습니다.
물론, 이 역시 철저히 이론적으로 타당하게 검토한 후 모형이 설정되어야 합니다 ㅎㅎㅎ
그래서 이론적 배경으로 ①, ② 에 대한 논리를 찾아야 합니다.ㅎ
① X -> Y
② X -> M, M -> Y
여기서 이론적배경은 흠... 힘드니까
바로 매개효과 확인하는 방법을 살펴보겠습니다. ㅋㅎ
-------------------------------------------------------------------------------------------------------------------------------
1. 매개모형 설정
KCYP2018 2차년도 자료에서 삶의 만족도, 부모의 자율성 지지, 학업열의 3가지 변수를 활용하겠습니다.
변수 만들기는 이전 챕터를 꼭 확인하시고 만들어주시기 바랍니다 ㅎㅎ
독립변수는 부모의 자율성지지
종속변수는 삶의 만족도
매개변수는 학업열의로 설정하겠습니다.
분석모형은 [그림 2]와 같습니다.
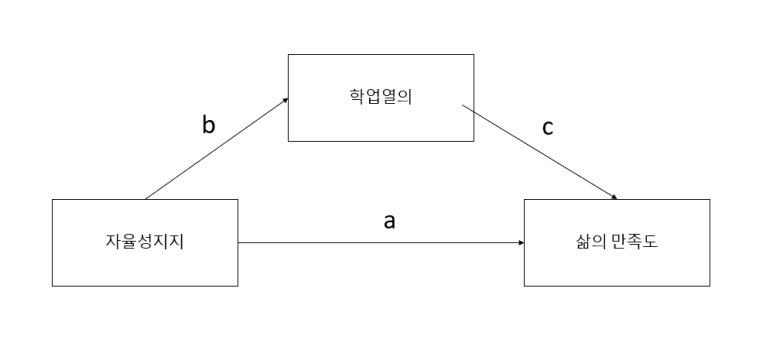
[그림 2] 분석모형
경로를 따라서 종속변수에 미치는 '총효과''총 효과'를 계산해보겠습니다.
먼저, 독립변수가 종속변수에 직접 영향을 미치는 '직접효과'를 회귀식으로 표현하면
삶의 만족도 = a*자율성 지지 (여기서 a는 회귀계수)
매개효과는 자율성 지지가 학업열의를 통해 삶의 만족도를 미치는 영향을 보는 것이니까, b와 c가 되겠습니다.
학업열의 = b*자율성 지지
삶의 만족도 = c*학업열의
이때 매개효과는 b*c 곱한 값으로 계산됩니다.
삶의 만족도에 미치는 영향력의 값으로는 'a'와 'b*c'가 되겠죠
따라서 삶의 만족도를 나타내는 총효과는a + (b*c)가 됩니다.
-------------------------------------------------------------------------------------------------------------------------------
이제 R로 분석실습을 해보겠습니다.
제가 R로 만든 변수는 다음과 같습니다.

[그림 3] 변수 생성 및 데이터 프레임 변환
지금까지는(기술통계, 상관분석, 회귀분석) 저 변수 이름 그대로 사용하였는데,,
매개효과 분석할 때 뒷부분에 문제가 생겨서 ㅎㅎ 먼저 이름을 바꾸도록 하겠습니다.

[그림 4] 데이터 프레임 열 이름 변경
방법은 간단합니다.
colnames(데이터셋) <- c("이름1", "이름2", "이름3")
제 데이터셋에는 열이 3개 있어서 이름을 백터에 3개를 넣은 것이죠
만약 4, 5개 이상이면 저 옆에 "이름4", "이름5" 넣으면 되겠죠?ㅎㅎ
혹시나 하나만 바꾸시길 원하신다면
colnames(데이터셋)[1] <- "이름1"
이렇게 대괄호(index)를 활용하면 됩니다
[1] : 첫 번째 행
그리고 잘 들어갔는지 head함수를 사용하면 바로 바뀐 이름을 확인할 수 있습니다.
-------------------------------------------------------------------------------------------------------------------------------
2. 매개 모형 검증 순서
매개효과 검증에는 대개 Baron & Kenny(1996)의 검증 순서를 따릅니다.
Baron, R. M., & Kenny, D. A. (1986). The moderator–mediator variable distinction in social psychological research: Conceptual, strategic, and statistical considerations. Journal of personality and social psychology, 51(6), 1173.
순서는 먼저 독립변수의 직접효과를 검증하고(a)
다음으로, 독립변수가 매개변수에 미치는 효과를 검증하고(b)
마지막으로 독립변수와 매개변수가 종속변수에 미치는 효과를 검증합니다(a, c)
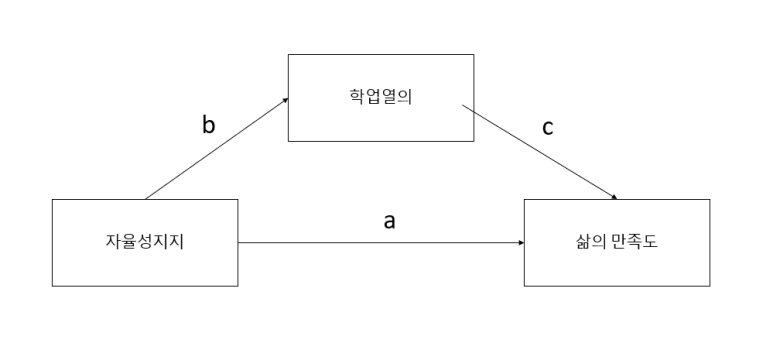
[그림 2] 분석모형
각 효과는 보다시피 회귀분석을 통해 분석을 합니다.
이때가 통계적으로 유의하느냐, 하지 않느냐에 따라 완전 매개, 부분 매개로 나누어집니다.
직접효과가 통계적으로 유의하다면, 종속변수에 미치는 변인이 독립변수와 매개변수 두 가지로
부분 매개효과가
반면, 직접효과 통계적으로 유의하지 않을 경우, 종속변수에 영향을 미치는 것은 매개 변수만 존재합니다.
이를 완전매개효과완전 매개효과가 있다고 합니다.
따라서, 회귀계수가 순서에 따라서 통계적으로 유의한 지 여부와 직접효과의 통계적 유의도를 따라서
완전 매개효과가 있는지, 부분 매개효과가 있는지 구분됩니다.
이 순서에 따라서 회귀분석을 한다면 다음과 같습니다.
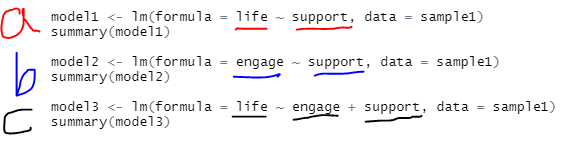
[그림 5] 매개효과 검증 순서
결과도 같이 보신다면
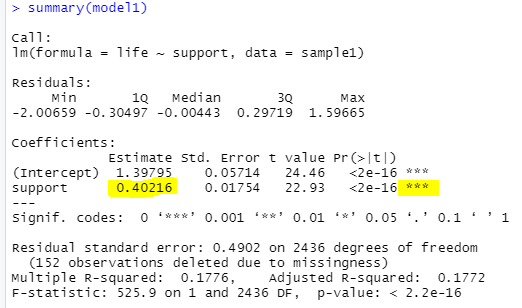
[그림 6] 회귀모형 a경로 결과
a 경로(직접효과)가 통계적으로 유의하네요 ㅎㅎ
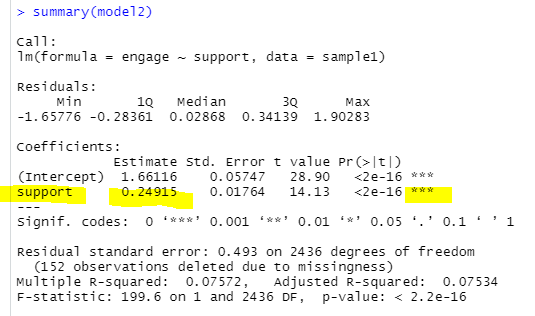
[그림 7] 회귀모형 b경로 결과
오 b경로도 통계적으로 유의합니다
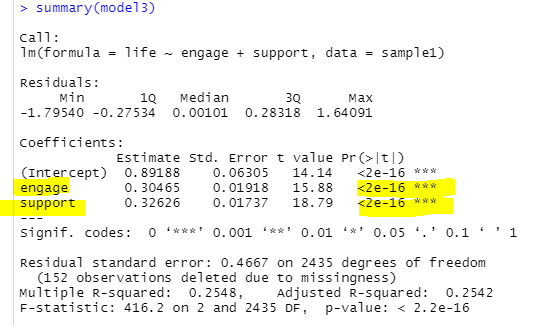
[그림 8] 회귀모형 a, c 경로 분석 결과
a, c 경로 모두 유의하네요!
그럼 이 모형은 부분매개효과부분 매개효과가 있는 것으로 보입니다. ㅎㅎ
-------------------------------------------------------------------------------------------------------------------------------
3. 매개효과 확인
이렇게 그냥 끝나면 좋겠는데 이제 매개효과가 진짜 유의한 지,, 실제 효과는 어느 정도인지 검증을 따로 합니다.
자주 사용하는 방법으로는 sobel test와 bootstrap 방법을 사용하는데요.
저는 bootstrap를 통해서 해보겠습니다.
매개효과 검증을 위해서는 sem함수가 필요합니다.
sem함수는 lavaan패키지의 내장 함수입니다.
설치를 해야겠죠?
[그림 9] lavaan 패키지 설치
그다음 모델을 만들어주어야 합니다
바로 예시로 보면서 이해하면 더 편할 것 같네요

[그림 10] 모델 생성
mediate <- '종속변수 ~ b*매개변수 + c*독립변수 -------------1
매개변수 ~ a*독립변수 -------------------------------2
indierct effect: = a*b -----------------------------------3
totaleffect: = c+(a*b)' ----------------------------------4
mediate라는 객체에 모델을 만들었습니다.
1번째 줄은 회귀분석에서 사용하는 식처럼 구성되어있습니다.
다만 'b'와 'c'로 각각 매개변수와 독립변수의 회귀계수를 문자로 표시를 하였습니다.
2번째 줄도
'a'로 독립변수의 회귀계수를 표시를 하였습니다.
3번째 줄은
4번째 줄은
직접효과인 'c'와 매개효과인 a와 b를 곱한 값인 'a*b'를 합한 값이 되는 것입니다.
모델을 구성하였으면, 이제 sem함수를 사용합니다.

[그림 11] 모델 분석
fit1 <- sem(모델, data = 데이터셋, se="bootstrap", bootstrap = 1000)
sem(모델) :아까 만든 모델 입력
se = 'bootstrap', bootstrap = 1000 : 부트스트래핑방법을 사용하며, 1000번 복원 추출하라는 명령어입니다.
부트스트래핑은 복원 추출을 통해서 유의도 검정을 하는 것이지요.ㅎㅎ
summary(fit1, standardized = T): 매개 모형을 요약해줍니다, 단 standardized = T를 설정함으로써 간접효과에 대해서 표준화계수로 나타납니다. (여기서 회귀계수는 비표준화 계수입니다!)
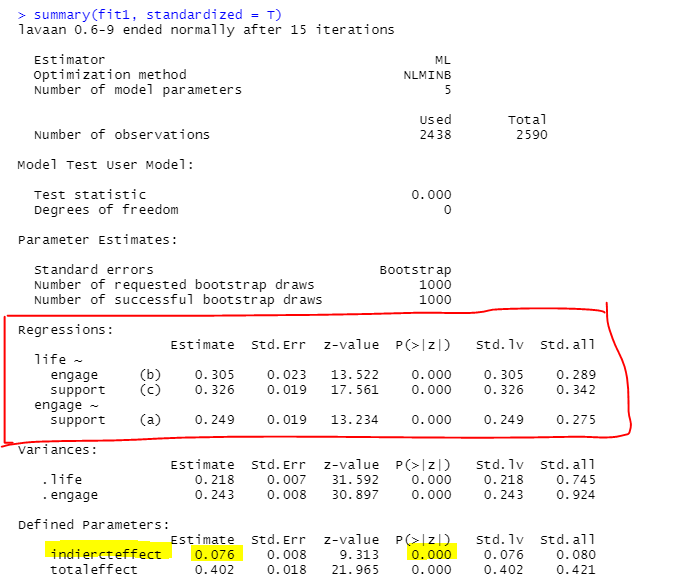
[그림 12] 매개효과 분석 결과
결측 값은 자동으로 제거해서 분석을 실시하였고
매개효과도 통계적으로 유의하게 나타났네요ㅎㅎ
아 그런데 한 가지 아쉬운 점이.. 매개효과 검증에서 95% 신뢰구간이 나오지 않아서 추가로 작업이 필요합니다.
이때 사용하는 함수는 parameterEstimates함수입니다.
sem 함수를 불러올 때 사용한 lavaan 패키지 내장 함수입니다.
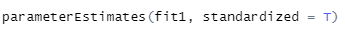
[그림 13] 신뢰구간 추정
parameterEstimates(sem함수 사용한 모델, standardized = T) 이렇게 입력하면 표준화된 값으로 결괏값을 제시해줍니다.

[그림 14] 신뢰구간 추정 결과
이제 내용을 정리해볼까요?
아 표준화 회귀계수값이 필요한데요 이건 저번 다중회귀해서 했듯이 lm.beat함수를 사용합니다!
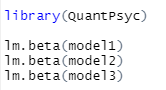
[그림 15] 표준화 회귀계수
순서는 앞서 검증순서검증 순서에 맞춰 입력합니다.
1. 독립변수 -> 종속변수
2. 독립변수 -> 매개변수
3. 독립변수, 매개변수 -> 종속변수
해석도 위 순서에 맞춰서 하면 됩니다.
1단계에서 독립변수가 종속변수에 통계적으로 유의한 영향을 주었다.
2단계에서 독립변수가 매개변수에 통계적으로 유의한 영향을 주었다.
3단계에서 독립변수와 매개변수가 종속변수에 통계적으로 유의한 영향을 주었다.
여기서는 직접효과도 통계적으로 유의하였으니 부분매개효과부분 매개효과가 나타났다고 하면 되겠군요

[그림 17] 매개효과 부트 스트래핑 결과
매개효과 검증 시에 신뢰구간도 같이 검증해서,
보고서에는 부트스래핑을 실시하였으며, 측정 횟수는 n=1,000 설정하였다. 매개효과 값은. 076이었고, 95% 신뢰구간에서
상한 값(. 093)과 하한 값(. 059) 사이에 0이 포함되지 않으므로 통계적으로 유의하다는 말을 해주면 되겠습니다!ㅎㅎ
그리고 마지막으로 모형에 표준화 계수를 삽입하여 같이 넣어주면 좋습니다.
그림은 PPT애용합니다..ㅎㅎ
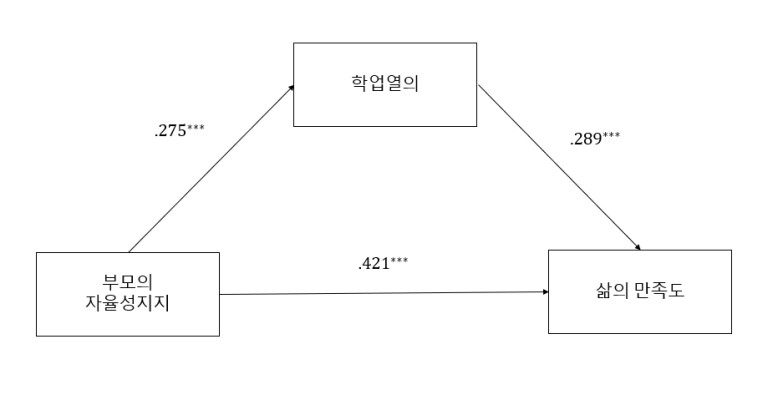
[그림 18] 매개효과 분석 모형 제시
보고서에 쓸 때에는 다중회귀에서 했듯이
기술통계, 상관관계 분석 꼭 같이 넣어야 하고
다음으로 매개효과 검증 순서, 매개효과 부트 스트래핑 결과, 매개효과 모형 같이 넣어주면 충분하지 않나 싶습니다!
이상으로 매개효과 분석 살펴보았습니다.
다음엔 조절효과 분석에 대해서 알아보겠습니다.
감사합니다.
'교육통계 > Rstudio' 카테고리의 다른 글
| 교육통계 R랑가몰라 4. 조절효과 2) 연속형변수 (0) | 2022.11.02 |
|---|---|
| 교육통계 R랑가몰라 4. 조절효과 1) 범주형변수 (0) | 2022.11.02 |
| 교육통계 R랑가몰라 2. 기초통계 - 4) 다중회귀분석2 (0) | 2022.11.02 |
| 교육통계 R랑가몰라 2. 기초통계 - 2) 회귀분석 (0) | 2022.11.02 |
| 교육통계 R랑가몰라 2. 기초통계 - 1) 상관관계 (0) | 2022.11.02 |