안녕하세요. 이번에는 상관관계 분석을 알아보도록 하겠습니다.
상관관계란 변수들, 변인들 간의 관계를 보여주는 통계치로
독립변인과 종속 변인들 간의 관계를 보기 전에 두 변인 간의 관계성을 확인할 수 있는 통계치라 할 수 있습니다.
-------------------------------------------------------------------------------------------------------------------------------
1. 산포도
상관계수를 확인하는 단계로 먼저 산포도(scatter plot)을 통해 두 변인 간의 관계를 확인할 수 있습니다.
산포도란 변수들을 x, y 축에 놓고 각 변수의 값을 x, y 축으로 하는 공간에 점으로 표시하여 나타내는 그래프입니다.
그럼 바로 R로 그려볼까요
1장 기술통계에서 사용하였던 KCYP2018 중학생 패널조사 2차자료를 사용하겠습니다.
변수는 학업열의와 자아존중감 두 가지를 사용하겠습니다.
먼저 변수를 [그림 1]과 같이 만들어 줍니다.

[그림 1] 분석을 위한 변수 만들기
분석을 편하게 하기 위해 이 두 변수를 데이터프레임 하나로 만듭니다.
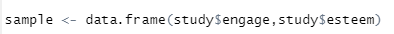
[그림 2] 데이터프레임 만들기
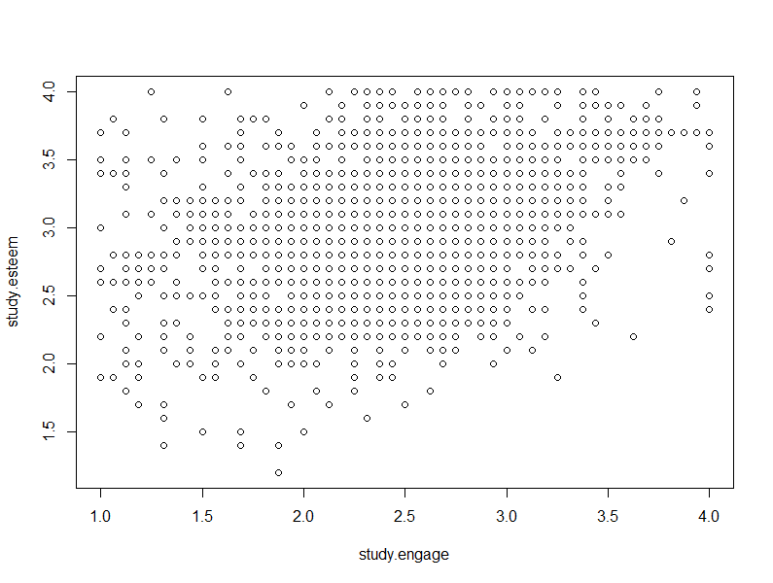
산포도를 만드는 함수는 plot(객체)입니다.

[그림 3] 산포도 그리기
그러면, Rstudio의 Plots 탭에 그림이 그려집니다.
저는 [그림 4]처럼 그려지네요
[그림 4] 산포도 그리기
이렇게 그림을 넣을 때, x축과 y축의 이름을 바꿀 수도 있습니다.
plot(객체, xlab = "이름1", ylab = "이름2")
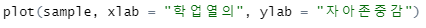
[그림 5] 산포도에 이름 넣기
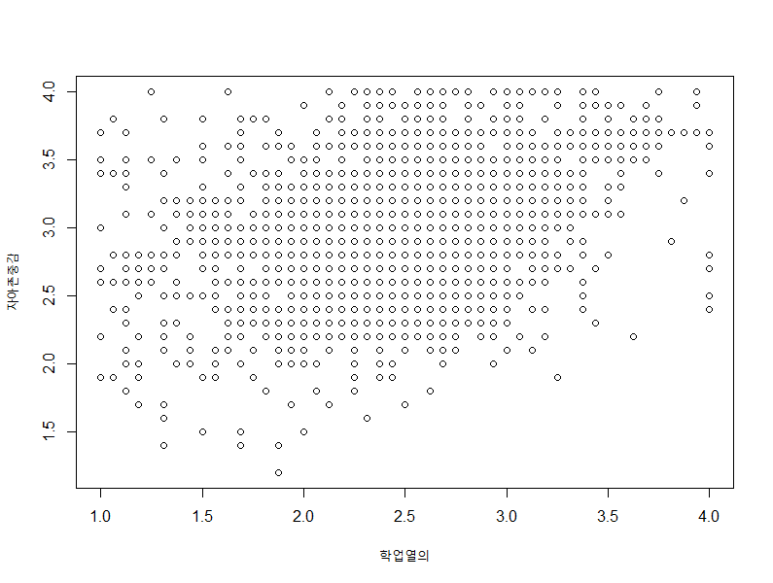
[그림 6] 산포도 그리기 2
한글도 잘 들어가네요ㅎㅎ
아 혹시나 하는 마음에 그림 넣기 방법을 알려드리면
plots 탭에 보면 Export 단추가 있습니다.
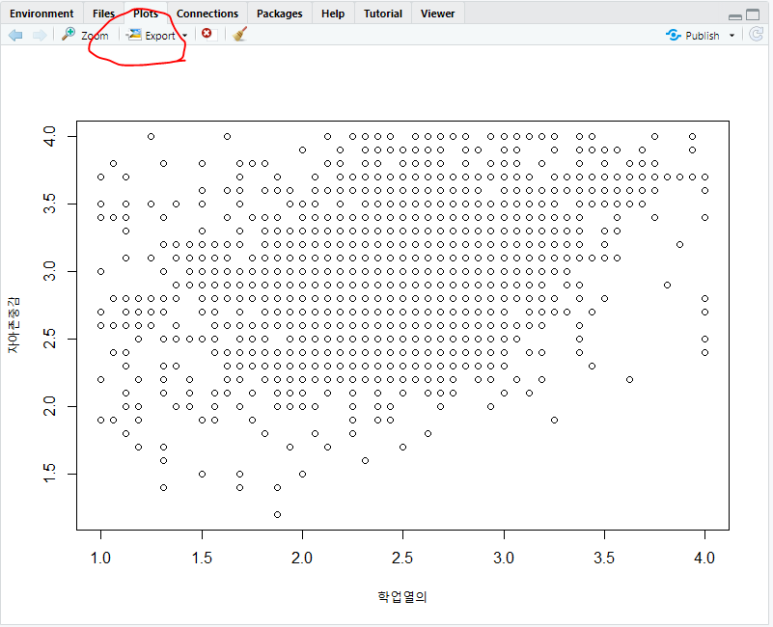
[그림 7] 그림 저장하는 방법
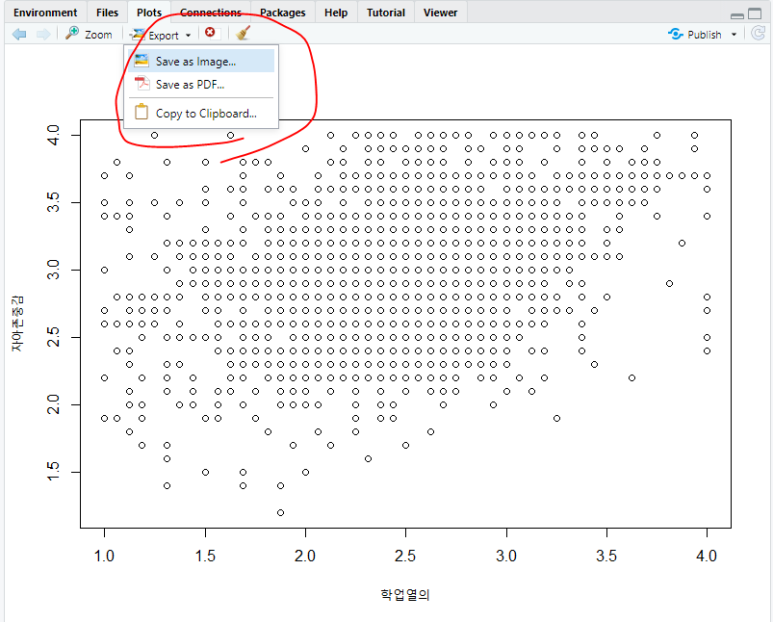
[그림 8] 그림 저장하는 방법 2
Image는 사진 파일로,PDF는 pdf파일로, Clipboard는 클립보드로(...ㅎ) 저장 또는 복사할 수 있습니다.
저는 Clipboard를 사용했습니다
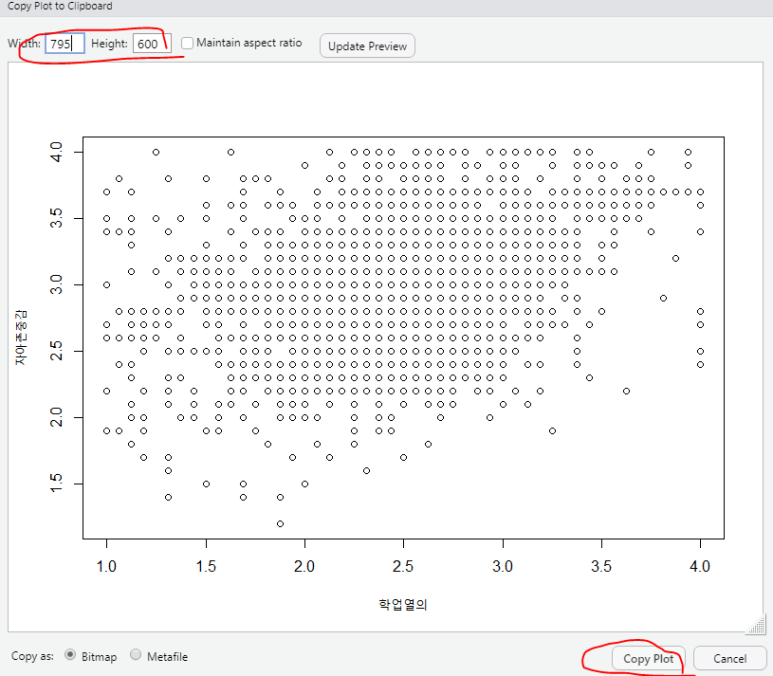
[그림 9] 그림 저장하는 방법 3
Copy plot 클릭하시면 바로 복사가 되어서 붙이고자 하는 문서에 바로 Ctrl+V로 붙이면 됩니다.
혹은 왼쪽 상단에 숫자를 조정해서 사진 크기를 조정할 수도 있답니다!
정리하면, 산포도를 보니 변수 관계가 약간 우상향 하는 방향으로 나타나는 것으로 보이네요ㅎ
아마 상관관계도 + 값으로 나타날 것 같습니다.
2. 상관관계
상관관계는 사실 앞선 역문항 만드는 방법에서 잠깐 사용했습니다.
사용하는 함수는 cor(객체)이면서, 조사자료에 결측 값이 있는 것을 대비하여
cor(객체, use = 'complete.obs', method = 'pearson') 으로 사용하길 추천드립니다.
객체 = 사용하고자 하는 데이터 셋
use = 'complete.obs' : 결측 값 완전 제거
method = 'pearson' : 피어슨 상관계수 사용
그러면, 학업열의 와 자아존중감의 상관관계를 살펴보겠습니다.

[그림 10] 상관관계 분석 코드

[그림 11] 상관관계 분석 결과
음 예상대로 +값이 나왔네요. 학업열의와 자아존중감의 상관계수는 0.331 정도 나타납니다.
한 가지 아쉬운 점이 있는데.. 통계적 검증이 필요하죠.
통계적으로 유의하지 않는데 숫자만 나타나면 어디다 쓰겠습니까ㅎ
이를 위해 사용하는 함수는 cor.test(x, y, use = 'complete.obs', method = 'pearson' ) 입니다.
x = 변수 1
y = 변수 2
맞춰서 넣으면 [그림 12]와 같이 됩니다.
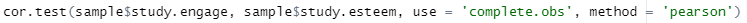
[그림 12] 상관계수 검정 코드
sample$study.engage : sample이라는 데이터셋에서 study.engage 열을 변수 1로 설정
sample$study.esteem: smaple이라는 데이터셋에서 study.esteem 열을 변수 2로 설정
결과는 [그림 13]처럼 나옵니다.
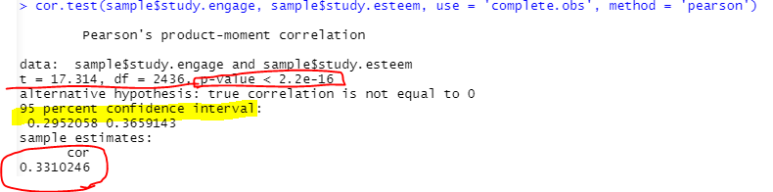
[그림 13] 상관계수 검정 결과
t검정을 통한 p-value 값을 보고해주면서 95% 신뢰구간, 상관계수까지 보고를 해주네요
보다시피 2.2e-16이니까 0.00000000000000022 쯤 일 것 같네요 ㅎㅎ
그래도 뭔가 아쉬운 것이... 변수 1개씩 넣으면 또 귀찮습니다.
그래서 기술통계에 사용했던 psych 패키지를 사용하겠습니다.
psych 패키지를 설치 및 로드하신 후에
psych 패키지 내장 함수인corr.test를 사용합니다.
corr.test(객체,use = 'complete.obs', method = 'pearson' )

[그림 14] 상관계수 검정 코드 2
실행하면 [그림 15]와 같은 결과를 얻습니다.
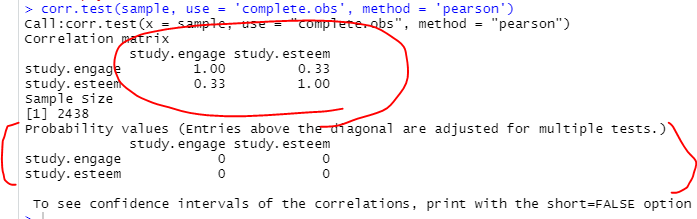
[그림 15] 상관계수 검증 결과 2
보다시피 상관계수 값과 함께 아래에 유의도 검정 값도 보여줍니다.
모두 '0'인 것으로 보아 두 변수의 상관관계는 통계적으로 유의한 것으로 보입니다.
다만, p-value의 정확한 값을 보여주지 않는 것은 이 코드의 단점이네요..
논문이나 보고서에 결괏값 보고 시유의 수준에 따라 플래그(*)를 붙여야 하는데 말이죠
그래서 먼저 전체 변수를 corr.test로 점검한 다음, 유의한 변수끼리 따로 cor.test함수를 사용하여
확인해야 할 것 같습니다..ㅠ
참고**
유의 수준 0.05 에서 통계적으로 유의할 때 -> *
유의 수준 0.01 에서 통계적으로 유의할 때 -> **
유의수준 0.001에서 통계적으로 유의할 때 -> ***
추가적으로 상관계수는 분야별로 상관이 강하다 혹은 약하다 표현이 다릅니다.
예를 들면 의학계에서는 0.99 아닌 이상 의미 없다 라는 이야기를 들은 것 같고요
사회과학분야에서는 0.3 정도만 나와도 오 괜찮은데..? 라며 오히려 0.7,8,9 이렇게 높게 나오면
변수 잘못 만든 거 아니냐고(공분산성 확인 필요라든가) 뭐라 합니다..ㅋㅋㅋ
저는 교육분야에 있기 때문에...ㅋㅋ 사회과학에서 사용하는 해석을 참조하겠습니다.
|
상관계수
|
해석
|
|
|
0.20 미만
|
거의 무시할 만한 상관관계
|
|
|
0.20 ~ 0.40 미만
|
낮은 상관관계
|
|
|
0.40 ~ 0.70 미만
|
비교적 높은 상관관계
|
|
|
0.70 ~ 0.90 미만
|
높은 상관관계
|
|
|
0.90 이상
|
매우 높은 상관관계
|
|
또는 관련 분야 선행연구들에서 상관계수 해석하는 것을 참조하는 게 좋을 것 같습니다.
여기까지 해서 산포도와 상관관계 분석을 R을 통해서 알아보았습니다.
상관관계는 회귀분석의 기초가 되는 통계치이기 때문에 참 중요한 수치입니다.
다음에는 회귀분석회귀분석에 대해서 알아보겠습니다.
감사합니다!
'교육통계 > Rstudio' 카테고리의 다른 글
| 교육통계 R랑가몰라 2. 기초통계 - 4) 다중회귀분석2 (0) | 2022.11.02 |
|---|---|
| 교육통계 R랑가몰라 2. 기초통계 - 2) 회귀분석 (0) | 2022.11.02 |
| 교육통계 R랑가몰라 - 1. 기술통계 4) 기술통계 결과확인하기 (0) | 2022.11.02 |
| 교육통계 R랑가몰라 - 1. 기술통계 3) 역문항 포함된 변수 만들기 (0) | 2022.11.02 |
| 교육통계 R랑가몰라 - 1. 기술통계 1) 자료불러오기 (0) | 2022.11.02 |