1. 잠재성장모형 명령문
잠재성장모형도 살펴볼께요.
먼저 데이터부터 합쳐야겠군요.
R에서 한 것과 마찬가지로
데이터는 KCYP2018 1-3차년도 사용합니다.
간단하게(?) 시간에 따른 중학생의 우울이 어떻게 변화하는지,
우울에 어떤 변인이 영향을 주고 있는지 살펴볼까 합니다.
일단 spss로 자료를 합치기 위한 준비를 하고

데이터-파일합치기-변수추가로 세 가지 파일을 하나로 합쳐줍니다.
기준변수로 HID, PID를 모두 사용합니다.
그래서 우울변수가 하나로 다 몰리게 한 다음에
dat파일로 저장해줍니다.
저장 전에 너비와 소수점 모두 통일해줍니다.
파일이 잘 합쳐졌다면..
data: file = growth.dat;
format = 7F12.2;
variable:
names = HID PID gender helpless1 sad1 sad2 sad3;
usevariables = gender helpless1 sad1 sad2 sad3;
Model:
i by sad1@1 sad2@1 sad3@1;
s by sad1@0 sad2@1 sad3@2;
[sad1@0 sad2@0 sad3@0];
[i s];
i on gender helpless1;
s on gender helpless1;
output: standardized;
여기서 포인트는
i : 초기수준 설정
s: 변화수준 설정
으로 정리해주고,
초기수준이니까 @1로 동일하게 고정해주고
변화수준은 @0 @1 @2 로 고정해줍니다.
그리고
초기값과 변화값에 성별과 학업무기력이 영향을 주는 것으로 설정을 해주고 돌리면 되겠습니다.
i on x1 x2
s on x1 x2
2. 결과 확인
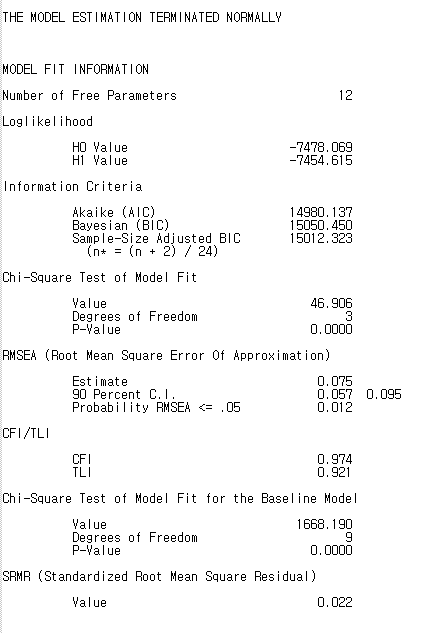
모형 적합도 확인해주시고
(R에서 돌렸을 때는 -값 나오던 CFI, TLI..신기하네..)
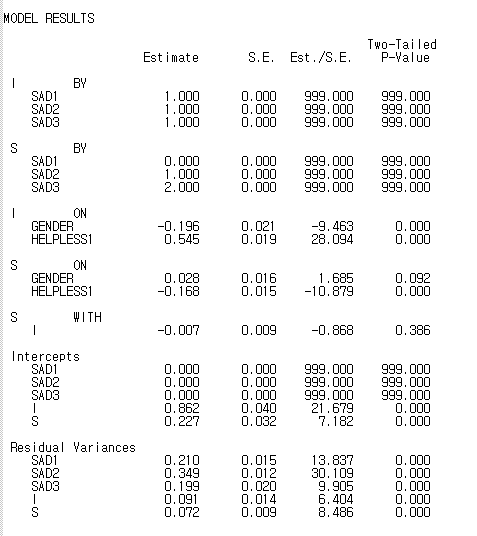
비표준화값 확인 해주면 되겠습니다.
우울의 초기수준, 변화수준은 통계적으로 유의미하게 나왔습니다.
(.862 / .227)
성별은 변화율에 통계적으로 유의미한 영향을 주지 않는 것으로 나타났고,
초기수준과 변화율의 상관도 통계적으로 유의미하지 않게 나왔습니다.
잔차 분산은 모두 통계적으로 유의하게 나와서,
개인차가 존재하는 것으로 보면 될 것 같습니다.
https://gaenodapeagles.tistory.com/22
교육통계 R랑가몰라 9. 구조방정식(SEM) 4) 잠재성장모형
지금까지 뭔가 올렸던 것은 횡단 연구 방법이었습니다. 횡단만 다루면 조금 아쉬운 부분이 있죠 횡단 연구의 장점으로 일반적인 경향을 파악하고, 개인 간 비교가 용이한 점은 있지만 1. 개인의
gaenodapeagles.tistory.com
(계수에 대한 자세한 설명은 여기를 참조해주세요..ㅎ)
마지막으로 여기 그림도 살펴보면,
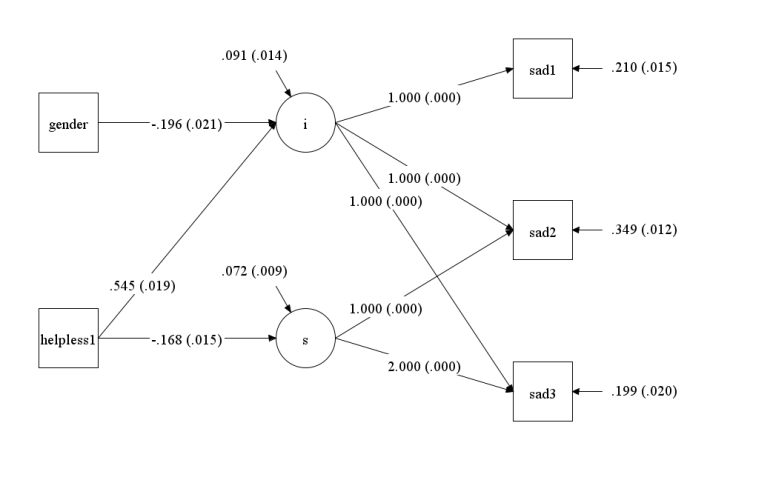
깔끔..(?)
'교육통계 > Mplus' 카테고리의 다른 글
| Mplus 5. 자기회귀교차지연모형 (0) | 2022.11.18 |
|---|---|
| Mplus 3. 경로모형 (0) | 2022.11.18 |
| Mplus 2. 탐색적 요인분석 (0) | 2022.11.17 |
| Mplus 1. 확인적 요인분석 (0) | 2022.11.16 |