- Mplus 자료 불러오기
일단 자료부터 불러와야겠죠
유독 다른 통계프로그램에 비해
자료 불러오는게 좀 까다로운 것 같습니다.
일단 제가 아는 방법은 dat 파일 형식과 csv 파일 형식으로 불러오는 방법인데요.
먼저 dat 파일 형식을 설명드리자면,
SPSS부터 갑니다..ㅋㅋㅋ
KCYP 2010 5차년도 자료를 생성해서,
자아존중감만 남기고 모두 삭제해보겠습니다.
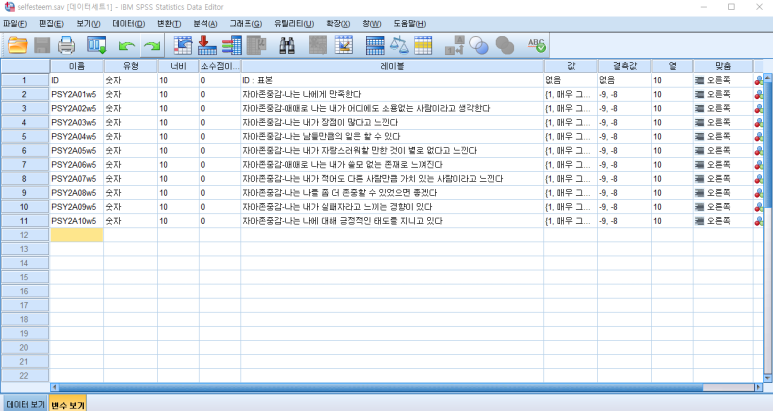
여기서 파일탭- 다른 이름으로 저장 을 눌러줍니다.

그 다음 저장유형 목록에서 "ASCII(*dat.)를 눌러줍니다.
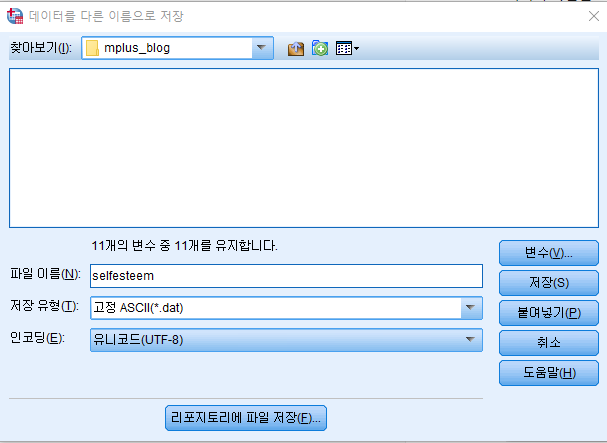
저장을 하면 '.dat'파일 형식으로 저장이 됩니다.
이제 Mplus를 실행해줍니다.

이런 기본화면에서 Mptext1 이라고 명령어 적는 시트가 하나 떠있습니다.
아이 1이 싫다. 2에서 하고 싶으신 분은

저 흰색 A4 용지 같은 걸 눌러주면 새로 하나 뜹니다.
암튼 이제 명령어를 적어볼까요

DATA: file = selfesteem.dat;
format = 11F10.0;
Variable:
names = ID self1 self2 self3 self4 self5 self6 self7 self8 self9 self10;
usevariable = self1 self2 self3 self4 self5 self6 self7 self8 self9 self10;
model:
SELF by self1 self2 self3 self4 self5 self6 self7 self8 self9 self10;
output:
standardized;
하나 하나 천천히 뜯어볼께요.
DATA: file = selfesteem.dat;
format = 11F10.0;
항상 명령어 적을 때 끝에 세미 콜론(;)으로 끝나는게 중요합니다.
첫째줄은
DATA: 라는 명령어를 넣어서 인식되면 알아서 파란색으로 변화합니다.
file = 파일명.파일형식;
그니까 selfesteem이라 하는 dat파일을 넣어둔 것이죠
format이 조금 짜증나는데요,
format = 변수개수F너비.소수점이하자리수;
이건 어케 확인하냐..SPSS에서 볼 수 있습니다..ㅋㅋㅋ
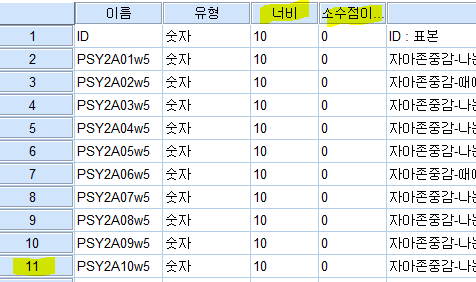
제가 만든 파일에서 변수는 총 11개를 사용하였고
저장할 때 너비는 10이였으며,
소수점자리는 0 이었습니다.
다음으로
Variable:
names = ID self1 self2 self3 self4 self5 self6 self7 self8 self9 self10;
usevariable = self1 self2 self3 self4 self5 self6 self7 self8 self9 self10;
여긴 좀 직관적이죠
Variable: 이 명령어를 입력하면 사용할 변수에 대해 써줍니다.
names = 입력한 변수에 대한 이름을 임의로 써주면 됩니다. 굳이 뭐 원래 변수명 안써도 되고
저는 자아존중감이라 그냥 self1...10으로 했습니다.
여기서 주의할 점은 데이터에 불러온 모든 변수에 대해 넣어주어야 합니다.
안 그러면 에러 메시지 떠요
usevariable = 분석에 사용할 변수만 써주면 됩니다.
말그대로 내가 쓸꺼만 넣어주면 됩니다.
딱히 ID 변수는 쓸 것 같지 않으니 패스하였고 나머지 변수명 그대로 복붙합니다.
세번째
model:
SELF by self1 self2 self3 self4 self5 self6 self7 self8 self9 self10;
이제 분석 모형에대해 설명해줍니다.
Model: 이라 입력해서 활성화시켜주고
여기서 요인분석을 할꺼라서 'by'를 써주었습니다.
SELF 라는 잠재변수를 상정하고(임의로 이름 작성하면 됩니다.)
, 이는 self1부터 self10까지로 구성되어있다고 보면 됩니다.
마지막으로 output
output: 이 명령어를 활성화시킨 다음
standardized; 표준화 값을 보여달라 명령어를 추가해줍니다.
2. 이거슨 확인적 요인분석
이 명령어는 확인적 요인분석에 해당합니다.
총 10개의 문항으로 1개의 요인을 분석해달라
이제 명령어를 다 썼으니 돌려봐야죠

명령어 창을 띄어논 상태에서 Run을 눌러줍니다.
그러면..

아웃풋 파일이 알아서 나옵니다.
(에러가 없었다면)
그러면 마찬가지로 모형 적합도값 확인해주고

문항별 적합도 값도 확인해주면 되겠죠?

살짝 당황스러운 점이
역문항들이 -(마이너스)로 안 나오고
다른 문항들에 비해 부하량이 .7이상으로 적절한 것처럼 나오네요 ㅋㅋㅋ
3. 그럼 CSV 형식으로는 어케 불러오지
마찬가지로 다른 이름 저장으로 가면 됩니다.
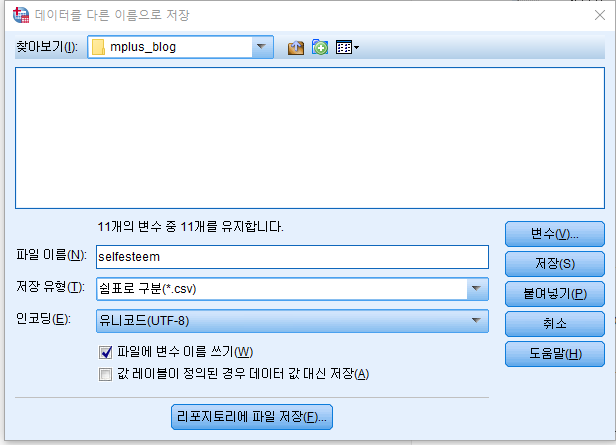
저장해주시고,
그럼 아까 명령어에서
format만 바꿔주면 될 것 같군요??

돌려볼까요?

바로 에러메시지..ㅋㅋㅋ
아 뭔데..
저장한 csv파일 열어줍니다.

아.. 변수명이 들어가있네요..
삭제해줍시다.
파일 저장하고 다시 돌려보아요
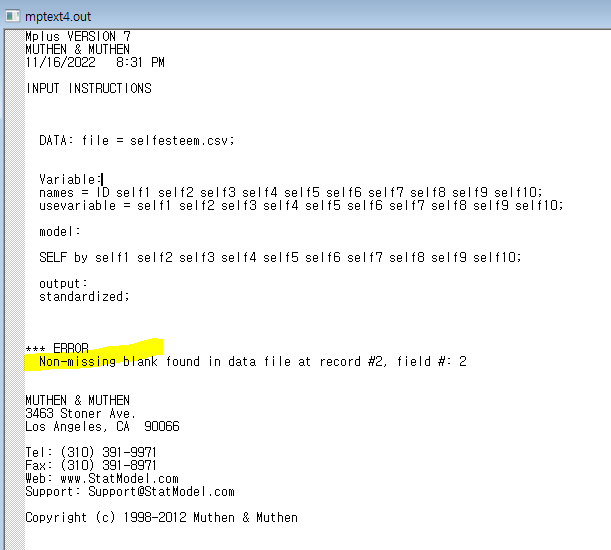
아 또 에러;;;
결측치 문제구나..
저장한 파일을 그냥 엑셀로 열어줍니다.
결측에다 999를 넣어 볼께요

결측 대체는
값 바꾸기에서 영역 설정한 다음 찾기 값에 스페이스 하나(공백),
바꾸기 값에 999를 넣으면 됩니다.
저장하신 다음,
명령어도 바꿔야겠죠??
DATA: file = selfesteem.csv;
Variable:
names = ID self1 self2 self3 self4 self5 self6 self7 self8 self9 self10;
usevariable = self1 self2 self3 self4 self5 self6 self7 self8 self9 self10;
missing = ALL(999.00);
model:
SELF by self1 self2 self3 self4 self5 self6 self7 self8 self9 self10;
output:
standardized;
missing 을 variable 안에 추가해줍니다.
그리고 RUN!
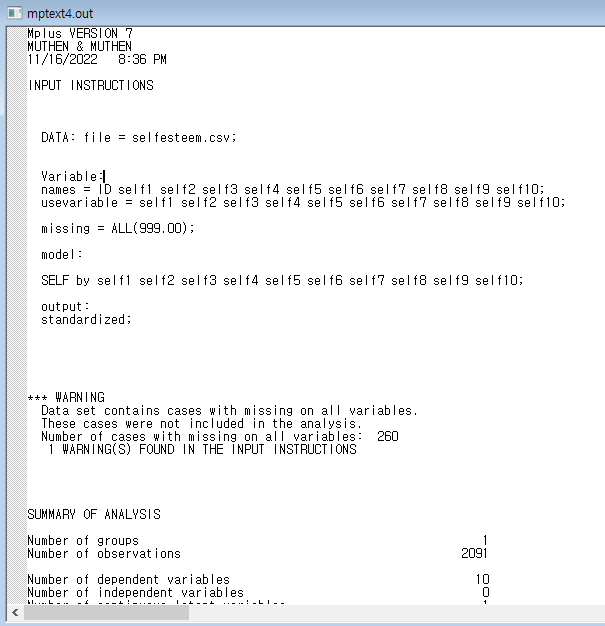
돌아갔네요...ㅋㅋㅋ
탐색적 요인분석은 다음장으로 패스!
'교육통계 > Mplus' 카테고리의 다른 글
| Mplus 5. 자기회귀교차지연모형 (0) | 2022.11.18 |
|---|---|
| Mplus 4. 잠재성장모형 (1) | 2022.11.18 |
| Mplus 3. 경로모형 (0) | 2022.11.18 |
| Mplus 2. 탐색적 요인분석 (0) | 2022.11.17 |