안녕하세요, 이번엔 구조방정식에 대해 알아보려 합니다.
이전까지 살펴보았던 회귀분석에서는
하나의 독립변수가 종속변수에 또는 여러 가지의 독립변수가 종속변수에 어떻게 영향을 주고 있는지를
분석하는 방법이었다면,
구조방정식은 회귀분석을 응용한 고급 분석방법이랄까요..
변수들 간의 관계를 회귀식으로 풀어내는 분석방법인데요..ㅎ
예를 들면, 학업열의 와 학업 무기력이 자아존중감에 미치는 영향을 분석한 것은 다중회귀분석을 사용했는데..
이 종속변수로 사용했던 자아존중감이 학업열의 나 학업 무기력에도 영향을 줄 수 있는 것은 아닐지
또 다른 '경로'를 생각해볼 수 있죠.
여기에 변수가 더 추가되면 훨씬 복잡한 회귀 식이 나오겠죠..?
아마 그래서 구조방정식(structural equation modeling)이라 불리는 이유가 될 것 같습니다.
1. 요인 분석
구조방정식은 요인 분석(factor analysis)이 포함됩니다.
요인 분석이란 잠재된 변인을 측정하는 문항들이 그 잠재된 변인을 잘 반영하고 있는지 검증하는 분석 단계입니다.
이전 회귀분석에서 변수를 구성할 때, 측정 문항에 대해 단순히 평균을 내어서 변수를 구정하였습니다.
하지만 구조방정식에서는 이 변수를 구성할 때, 한 단계 검증을 더 거치는 것입니다.
예를 들면, 자아존중감에 대해 총 10가지 문항으로 조사를 실시하였습니다.
그러면 이 10가지 문항이 정말 '자아존중감'을 잘 측정하고 있는지 검증하는 것이죠.

사회과학 분야에서 다루는 변수들은 대부분이 다 추상적인 변수들을 많이 사용하죠.
눈에 명확히 보이지 않고 이론적 개념이 대부분이니까요.
이렇기에 변수 구성에 대한 검증이 더 철저하게 물어보는 것 같습니다.
2. 요인 분석 종류
요인 분석의 종류에는
탐색적 요인 분석(Exploratory Factor Analysis: EFA)과
확인적 요인 분석(Confirmatory Factor Analysis: CFA)이 있습니다.
탐색적 요인 분석은 특별한 이론적 배경보다는 일단 주어진대로 요인분석을 실시해서, 결과값에 따른 요인을 구성하는 방법이고,
확인적 요인 분석은 이론적 배경에 근거하여 특정문항들은 어떠한 변인을 구성하고 있음을 제한하고 요인분석을 실시하는 방법입니다.
예를 들면, 문항이 10개로 구성된 설문이 있다고 가정해봅시다.
탐색적 요인분석은 1번부터 10번까지 어떤 변수를 측정하고 있을지 기대하고 있지 않으므로
연구자가 만약 10개 문항에서 2개의 잠재 변수를 또는 3개의 잠재변수를 기대한다면 다음 그림과 같이 가정을 하고 분석이 된다고 할 수 있습니다.
탐색적 요인 분석
반면 확인적 요인 분석을 실시하는 경우에는
설문에서 1~5번 문항은 X1을, 6~10번 문항은 X2 변수를 측정하는 것을 가정해놓고 분석하는 것입니다.
확인적 요인분석
3. 요인 분석 연습
1) 탐색적 요인 분석
이제 R을 활용해서 탐색적 요인 분석해보려 합니다.
이번에 활용한 데이터는 KCYP 2010 5차 연도 자료입니다.
이 설문에서 학습습관에 대한 문항은 총 18문항으로,
하위요인으로 성취 가치, 숙달 목적 지향성, 행동통제, 학업시간관리 4가지 요인으로 구성되어 있습니다.
R로 탐색적 요인 분석을 해도 실제 4가지 요인으로 구분되는지 확인해보면 재밌을(?)것 같네요
요인분석을 위해 총 18문항을 따로 데이터 프레임으로 만들어줍니다.
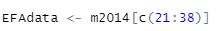
제가 불러온 데이터 프레임에서 21:38행이 학습습관 문항이었습니다.
그리고 결측 값을 처리해줍니다.
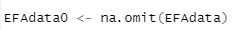
factanal 함수를 사용해서 이제 분석을 돌립니다.
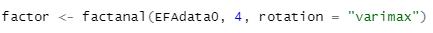
factanal(데이터셋, 요인 개수 설정, rotation = "varimax")
여기서 로테이션 설정이 중요한데요,
말 그대로 통계프로그램이 스스로 막 열심히 머리를 굴리면서 '회전'을 시키며
최적의 결괏값을 보여주는 명령어입니다.
그리고 print 함수를 써서 결과값을 불러옵니다.
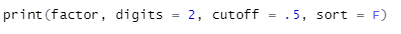
print(요인 분석 객체, 소수점 몇 자리, 컷오프 지점, 내림차순 설정)으로 보시면 됩니다.
여기서 cutoff 설정이 중요한데요
여기서 나타나는 요인 부하량은
0부터 1 사이의 값 중에서 당연 크면 클수록 서로 관련이 높다고 볼 수 있으며
좋은 값이라고 볼 수 있겠죠?
그래서 컷오프를 높게 설정해놓으면 더 명확하고 깔끔하게 보일 것 같습니다.
저는. 5로 두었는데
데이터를 사용하기에는. 6에서. 7 이상이 안정적이다 이렇게들 이야기하는 것 같아요.
결괏값을 보시면..
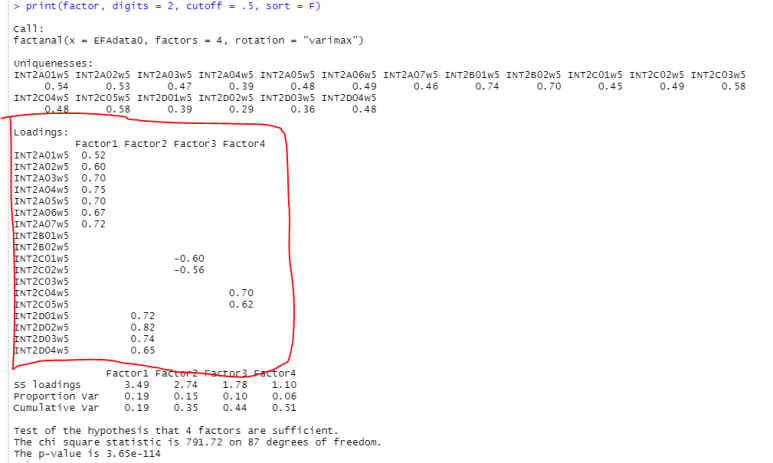
저기서 Loading만 보셔도 충분합니다...ㅋㅋ(사실 다른 값들은 어떻게 쓰는지 잘... 딱히 보지도 않는 것 같고요..? 아마..?)
오우 설정을 4개로 해놓긴 했지만, 결괏값도 4개로 예쁘게 모여있네요.
문항별로 신뢰도를 분석해볼까요.
신뢰도 분석을 위해서는 'ltm' 패키지가 필요합니다.
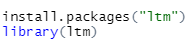
불러오신 다음에
descript 함수를 사용해서 신뢰도 계수를 구합니다.
첫 번째 요인으로 묶인 1번부터 7번까지를 예시로 보여드리면,
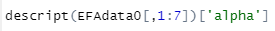
descript(데이터셋[ , 1열부터 7열까지)['alpha']
뒤에 'alpha'을 넣어야 Cronbach's alpha 값을 알려줍니다!..ㅎㅎ
그럼 결과는
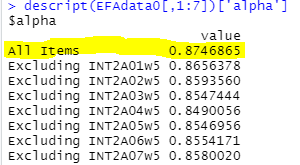
전체 ALL Items로 묶어서 신뢰도가 나오고
그다음 문항별 신뢰도를 계산해서 보여줍니다.
신뢰도에 따라 문항을 넣고 빼고 하시면서
최적의 신뢰도(?)를 구하시길 바랍니다..ㅋㅋ
. 9 이상 나오면 이상적이겠지만..
최소. 7 이상은 나와주어야 쓸만할 것 같습니다..ㅎ
여기서 끝내면 아쉽다고 배운 것 같아서...ㅋㅋㅋ
하나 더 해야 합니다..ㅠㅠ
"eigenvalue" 값을 확인하면 더 안정적으로 변수를 구성할 수 있는데요
사전적 정의 그대로 고윳값으로, 요인이 몇 개까지 포함해야 고윳값을 잃지 않는 것으로 볼 수 있는지 확인해주는
뭐 그런... eigenvalue 값이 1 이하로 내려가기 전에 몇 개의 요인을 나타내는지 보여주는 뭐 그런.. 거라는 것 같은데요...?ㅎㅎ
이 값을 확인하기 위해서는 "nFactors" 패키지가 필요합니다.
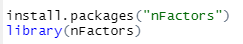
불러오신 다음에
eigen 함수를 사용해서 데이터를 넣어주고..

parallel 함수도 사용해서 몇 가지 더 설정을 해주고...

nScree 함수를 사용해서 또 몇 가지 입력을 해준 다음..
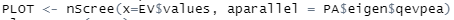
마지막으로 plotnScree를 통해서 불러오기만 하면...!
이런 결과를 얻습니다..!! 휴,..
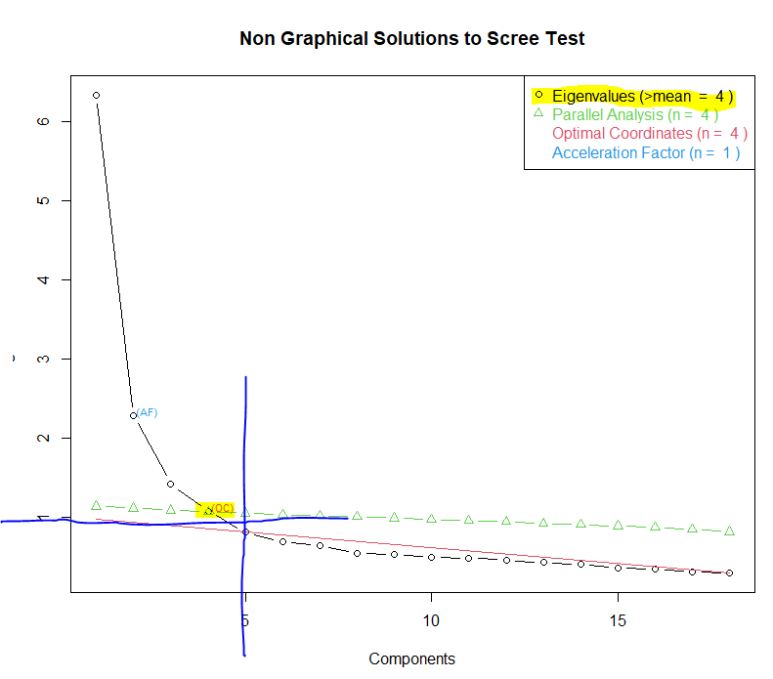
보고자 했던 Eigenvalues를 보시면 요인 개수가 4개 일 때 까지는 좌측 그래프에서 1 이상에 있으나
5개 이상부터는 1 이하로 값이 떨어집니다.
이걸 보고 아 요인을 4개로 정하면 되겠구나..!라고 결과를 얻었다고 보면 되겠습니다..ㅎㅎ
그러면 앞에서 4개 요인으로 나누어졌던 것을
이렇게 저렇게 책도 보고 논문도 보고 이론적 배경을 구성해서
나는 1번, 뭐 2번 뭐 3번은 뭐 4번은 뭐뭐라고 하위요인들을 명명하고
다음 분석을 진행하시면 되겠습니다.
글이 너무 길어진 관계로.. 확인적 요인 분석은 다음 장으로 돌려보겠습니다..ㅎㅎ
감사합니다!
'교육통계 > Rstudio' 카테고리의 다른 글
| 교육통계 R랑가몰라 9. 구조방정식(SEM) 2) 모형검증 (0) | 2022.11.03 |
|---|---|
| 교육통계 R랑가몰라 9. 구조방정식(SEM) 1) 요인분석(확인적요인분석) (0) | 2022.11.03 |
| 교육통계 R랑가몰라 8. 다항(서열)로지스틱 회귀분석 (0) | 2022.11.02 |
| 교육통계 R랑가몰라 7. 로지스틱 회귀분석-2(분석) (0) | 2022.11.02 |
| 교육통계 R랑가몰라 7. 로지스틱 회귀분석-1 (이론..?) (0) | 2022.11.02 |