다층 모형 분석을 하려면 그에 적합한 데이터가 필요하다
당연 1수준, 2수준 정보가 포함되어 있는 데이터를 활용해서
이 둘을 통합, merge를 해야 한다.
데이터 만드는 작업을 R, STATA, SPSS로 함 해보았다
활용한 데이터는 KEDI 교육종단연구 2013 1차년도 학생, 학교장 자료를 사용하였다.
앞으로 분석 연습에
종속변수는 창의성
1수준 변수는 수업태도
2수준 변수는 학교운영방식, 사립더미
이렇게 쓴다 생각하고 변수를 만들어보았다 ㅎㅋㅋ
기본 데이터는 SPSS용 SAV를 사용한다
먼저 R부터
1. 데이터 불러오기
R로 SPSS 데이터를 불러오려면
haven 패키지가 필요하다
haven 설치후 불러오고
학생, 학교 자료를 R로 불러온다

경로에 당연 데이터가 있어야 하고
(따로 폴더 만들어서 워킹디렉토리 만드는 거 개추..)
만약에.. 데이터가 저기 저 멀리 C드라이브.. D드라이브 어딘가 있다면..
뭐 우짜겠노.. 경로를 직접 입력해서 불러와야제 ㅋㅋㅋ
tidyverse 패키지의 str_c를 활용해서
현재 경로 확인 -> getwd()

그 다음 str_c 함수를 이용해서 경로와 파일명을 섞어서 불러와준다

str_c(getwd(), "/", "student.sav")
이렇게 실행하면

경로를 묶어줄 수 있다
이 경로외에 다른 경로가 또 섞여 있으면..
뭐 타이핑 해야지ㅋㅋ

"", "" 사이에 적절히 경로를 쓱아 주면 가능..
암튼 이렇게 학생, 학교 데이터를 불러온다
2. 데이터 편집
수많은 변수들.. 지금은 필요없다
내가 필요한 것만 선택
tidyverse의 select 활용
student %>% select(L2SID, L2Y1_SCHID, starts_with("L2Y1S11"), starts_with("L2Y1S04")) -> stu_trim
school %>% select(L2Y1_SCHID, L2Y1_SCHTYPE, starts_with("L2Y1R08")) -> sch_trim

이건 앞서 많이 다루었으니..
다음으로 변수도 만들어주고
stu_trim %>%
mutate(창의성 = apply(.[,str_detect(colnames(stu_trim),"L2Y1S04")],1,mean, na.rm = T),
수업태도 = apply(.[,str_detect(colnames(stu_trim),"L2Y1S11")],1,mean, na.rm = T)) -> stu_trim
변수 생성도 Rstudio 머시기 다루는 장에서 다루었으니..
궁금한 사람은 가서 보고 오심이..ㅎㅋㅋ

결측치도 제거해주고
na.omit(stu_trim) -> stu_clean
그다음 write_sav 를 사용해서 일단 sav 파일로 저장해보자

아오..spss시치..
위대한 한글을 인식하지 못한다..
변수명을 영어로 돌아가자..
stu_trim %>%
mutate(creative = apply(.[,str_detect(colnames(stu_trim),"L2Y1S04")],1,mean, na.rm = T),
attitude = apply(.[,str_detect(colnames(stu_trim),"L2Y1S11")],1,mean, na.rm = T)) -> stu_trim
그리고 저장하면

에러 없이 잘 된다..
학교 파일도 마찬가지 절차를 거쳐 일단 저장 ㅋㅋ
sch_trim %>%
mutate(management = apply(.[,str_detect(colnames(sch_trim),"L2Y1R08")],1,mean, na.rm = T),
private = case_when(L2Y1_SCHTYPE == 1 ~ "0",
L2Y1_SCHTYPE == 2 ~ "1", TRUE ~ "l")) -> sch_trim
na.omit(sch_trim) -> sch_clean
write_sav(sch_clean, "학교.sav")
3. 데이터 통합
통합에는 R내장함수인 merge를 써도 되나
이게 결측치나, 데이터상 변수의 속성이 다를 경우(A는 숫자(1), B는 텍스트("1"))
에러가 쥐도 새도 모르게 발생해서
나중에 물음표 살인마가 되버린다
아 맞게 했는데 왜 안되는데??
이 사단이 여러번 나기 때문에(경험담..ㅎ)
tidyverse의 left_join, right_join, full_join 시리즈를 사용할 것을 권장한다
이 친구들은 만약 형식이 다르면 자동으로 error 메시지로 알려준다
(너 이렇게 하면 제대로 안된다잉~ )
아까 잘라서 저장했던
stu_trim 과 sch_trim 에서 역시 필요한 것들만 쏙쏙 고르면

그리고
left_join 함수를 써보자

left_join(데이터 A, 데이터 B, by = "키변수")
키변수 없으면 데이터 안 합쳐진다
결측치 제거해주어야 되는데
일단 한 큐에 na.omit을 써서 제거해주어도 되고
아님 filter를 사용해서 특정 조건에 해당하는 것들만 제거해도 좋다
특히 종속변수 결측은 좀 거시기 하니까
merge %>% filter(is.na(창의성) != T)
이런식으로 제거해주면

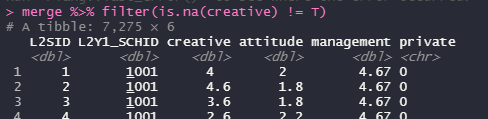
알아서 잘 빠져준다
그럼 일단 R에서는 다층 분석할 준비는 다 된 것 같다
'교육통계 > 다층모형' 카테고리의 다른 글
| 다층모형 - 3.데이터생성(STATA) (0) | 2023.09.06 |
|---|---|
| 다층모형- 4.횡단모형(R) (0) | 2023.09.06 |
| 다층모형 - 3.데이터생성(SPSS) (0) | 2023.09.04 |
| 다층모형 - 2.기본 구조 (0) | 2023.09.04 |
| 다층모형 - 1. 이거 왜함? (0) | 2023.09.04 |