그럼, 다층구조를 반영해서 식을 작성해보면 어떻게 될까

원래 보던 회귀식에서 아래 첨자들이 추가 되었다
다층구조가 적용된만큼, 그 수준을 반영하여 식이 표기된 것으로 보면 된다
이제 종속변수는 j번째 학교의 i 번째 학생을 나타내는 값이 된다
1. 오차가 두 개?
설명변수를 제외하고 다시 식을 작성해보자
절편과 오차항만 남아 있게 되는데
절편을 한 번 더 해부 해보려 한다
해부해보면
40개의 학교가 있다면,
j 번째 학교의 점수가 있을 것이고
j 번째 학교 점수는 40개 학교의 평균 + 나머지 잔차로 설명할 수 있게 된다
이렇게 해부 한 ② 식을 ①에 넣으면
이렇게 표현할 수 있다
예를 들어 보자
40개 중학교 학생들의 국어성적 평균이 65점 이었고,
40개 학교 중 하나인 이글스 중학교의 평균은 70점,
이글스 중학교에 다니는 A 학생의 국어점수가 80점이다
그러면 이 80점이라는 점수를 ③ 식에 따라 분리해보면
A 점수 = 전체 학교 평균 + A 학교 잔차 + A학생 잔차
80 = 65 + 5 +10 이렇게 나눌 수 있다
이렇게 표현하면, 오차항이 두 개가 나오게 된다
2. 1수준 분산 + 2수준 분산 = 전체 분산
오차항이 두 개니까
분산도 두개가 추정된다
1수준 분산과
2수준 분산
이 두 가지 정보가 제공해주는 것이 무엇이냐 하면
집단 내 상관계수(ICC: intra correlation coefficient)를 산출할 수 있다
종속변수를 설명하는데 2수준 분산이 어느정도 차지하는가를 보여주는 지표로
사회과학분야, 특히 교육분야에서는 대충 20% 정도 넘는게 쉽지 않다고 한다
그런데 이 수치가 너무 낮을 경우 뭐 1-3% 정도 나오면
집단간 차이가 거의 없다고 봐도 무방하니
굳이 굳이 다층구조로 분석할 이유가 없지 않나 싶을 수 있다
즉, 이 것의 의미가 집단내 상관계수니까
독립성 가정을 살펴본다라고 보면 될 것 같은데
집단 내 서로 관련도가 높다면 다층구조로 분석할 여지가 충분할 것이고
집단 내 관련도가 낮게 나오면 굳이 굳이 다층구조로 볼 필요가 없는 것 아닌가
그런데
이 집단 내 상관계수로서 의미를 가지려면
꼭 어떤 설명변수도 넣지 않은 상태에서 봐야 한다
그 이후로 이 값을 보는 것은 크게 의미가 없어진다
수준에 따라 변수를 투입했을 때
변수 투입에 따라 분산이 어느 정도 설명되는지 확인해보는 것 정도?
3. 설명변수를 넣는다면?
이러한 기본구조에 학교수준 변수인 대학생교육봉사 프로그램 운영여부를 넣어보자
변수이름이 너무 길다.. 이하 P로 표기..
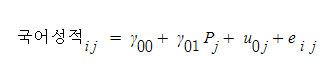
프로그램에 따른 기울기 계수가 추가로 붙고
이 계수가 유의한지 아닌지에 따라 해석을 하면 된다
만약에 1수준 변수도 즉, 학생 수준 변수도 있었으면 어떻게 될까?
학생수준 변수로 성별(남학생 더미)을 넣어본다면,
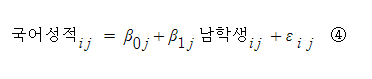
여기서 출발해보도록 하자
남학생 = 1 이면, 남학생의 국어점수
남학생 = 0 이면, 여학생의 국어점수를 나타내는 식이 되는데
④에 2수준 프로그램 변수를 넣으면
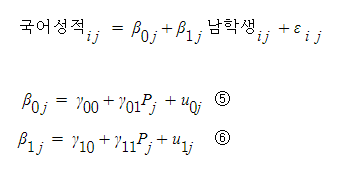
절편과 더불어서
1수준 변수 기울기에도 프로그램 변수가 들어가게 된다
기울기에도 프로그램 변수가 들어간 것의 의미는
성별에 따른 국어성적의 차이 역시
전체 학교의 남학생 더미 회귀계수가 존재할 것이고,
이에 따른 학교별 잔차가 존재할 것이라 가정하는 것이다
이 회귀계수에 프로그램 운영여부가 관련이 있는지를 또 살펴보는 것이
⑥ 식의 의미라고 볼 수 있다
그래서 ⑤, ⑥ 식을 다시 합쳐보면
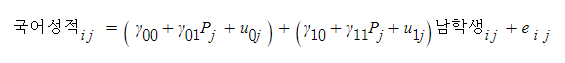
보기 정신 사나우니 다시 정리해보면,

어째 더 정신 사나워진 것 같지만 ㅋㅋ
변수가 추가됨에 따라 복잡한 식이 연출되었다
특히나 주목해볼 만한 것은 '상호작용항'과 '무선효과'
상호작용은 조절효과 분석에서 다루는 내용
여기서도 비슷하게 해석하면 된다
다만, 이것은 여기서 '층위간 상호작용항'으로 불리게 된다
무선효과는 기울기가 학교마다 다르냐, 같냐를 표기해주는 것
만약 이 무선효과가 통계적으로 유의하다면,
남학생더미, 성별에 따른 효과가 학교마다 다르게 작용하고 있다는 것을 보여주는 것으로 보면 된다
모형 설정은 이렇게 경우에 따라, 변수가 추가됨에 따라
더 복잡하게 설정할 수 있는데
복잡하면 복잡할 수록 통계적으로 유의하기 쉽지 않기 때문에
만약, 상호작용항이나 무선효과를 추정하고자 한다면
탄탄한 이론적 배경을 바탕으로 진행할 것을 추천..
대부분의 경우 절편에서만 변수 투입하고,
상호작용항이나 무선효과는 잘 하지 않는 것 같다
(논문 들 스윽 뒤져봤을 땐 그랬는데..)
추후 프로그램 돌릴는 내용 올릴 때
다시 자세히 살펴보려 한다
프로그램은 HLM이 제일 많이 사용되고
https://ssicentral.com/index.php/products/hlm-general/hlm-licenses/
적잖이 R이나 STATA가 사용되는데
...
셋 다 해볼까 생각중 ㅎㅋㅋ
'교육통계 > 다층모형' 카테고리의 다른 글
| 다층모형 - 3.데이터생성(STATA) (0) | 2023.09.06 |
|---|---|
| 다층모형- 4.횡단모형(R) (0) | 2023.09.06 |
| 다층모형 - 3.데이터생성(SPSS) (0) | 2023.09.04 |
| 다층모형 - 3.데이터생성(R) (0) | 2023.09.04 |
| 다층모형 - 1. 이거 왜함? (0) | 2023.09.04 |